Hazelcast 介绍与使用(整理)
要用到 Hazelcast 这个东西用作分布式缓存, 网上搜索了下发现这篇文章对我理解 Hazelcast 那种无主从之分, 避免了单点故障很有帮助, Hazelcast 的数据分布方式很有点像磁盘阵列 RAID 1, RAID0+1 的影子. 基本上在一个节点出现故障的情况下是不会影响数据访问的.
下面这个系列讲的很详细:
Hazelcast 是一个开源的可嵌入式数据网格(社区版免费,企业版收费)。你可以把它看做是内存数据库,不过它与 Redis 等内存数据库又有些不同。项目地址:http://hazelcast.org/
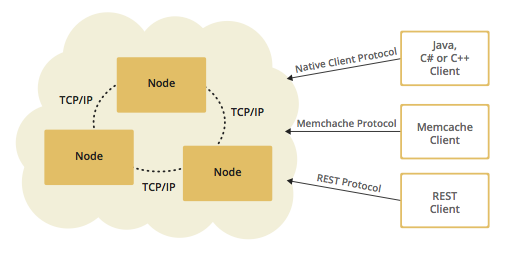
Hazelcast 使得 Java 程序员更容易开发分布式计算系统,提供了很多 Java 接口的分布式实现,如:Map, Queue, Topic, ExecutorService, Lock, 以及 JCache 等。它以一个 JAR 包的形式提供服务,只依赖于 Java,并且提供 Java, C/C++, .NET 以及 REST 客户端,因此十分容易使用。
Hazelcast 缺省情况下把数据分为 271 个区。这个值可配置于系统属性
下例是拥有2个节点的 Hazelcast 集群:
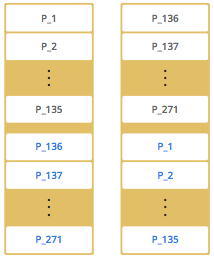 黑色字体表示分区,蓝色字体表示备份。节点1存储了1到135分区,这些分区同时备份在节点2中。节点2存储了136到271分区,并备份在节点1中。
黑色字体表示分区,蓝色字体表示备份。节点1存储了1到135分区,这些分区同时备份在节点2中。节点2存储了136到271分区,并备份在节点1中。
此时如果添加2个节点到集群中,Hazelcast 一个一个的移动分区和备份到新的节点,使得集群数据分布平衡。
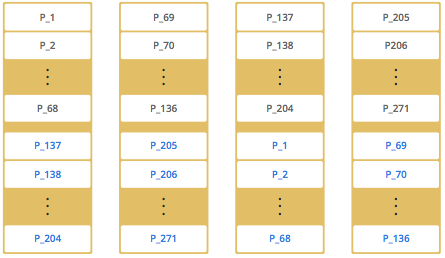 注意实际中分区并不是有顺序的分布,而是随机分布,上面的示例只是为了方便理解。重要的是理解 Hazelcast 平均分布分区以及备份。
注意实际中分区并不是有顺序的分布,而是随机分布,上面的示例只是为了方便理解。重要的是理解 Hazelcast 平均分布分区以及备份。
Hazelcast 使用哈希算法进行数据分区。对于一个给定的键(如Map)或者对象名称(如topic和list):
每个节点维护一个分区表,存储着分区号与节点之间的对应关系。这样每个节点都知道如何获取数据。
注意: 如果最老的节点挂了,次老节点会接手这个任务。
这个定时任务时间间隔可配置系统属性
重分区发生在:
此时最老节点会更新分区表,分发,接着集群开始移动分区,或者从备份恢复分区。
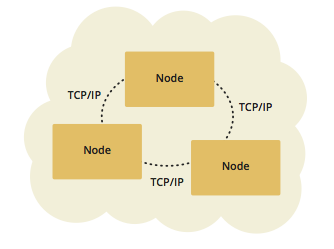
有两种方式:嵌入式和客户端服务器。
 摘自: http://www.cnblogs.com/seasonsluo/p/hazelcast-intro.html
摘自: http://www.cnblogs.com/seasonsluo/p/hazelcast-intro.html
以下是两段使用 Hazelcast 作为分布式 Map 和 Topic 的例子
启动后会看到输出
即使是本地的启动方式也会打开 Socket 端口, 默认在本机启动两个不同的端口号. 其他 Hazelcast 的应用例子可参考 https://hazelcast.org/.
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
下面这个系列讲的很详细:
- Hazelcast集群服务(1)——Hazelcast介绍
- Hazelcast集群服务(2)——Hazelcast基本配置
- Hazelcast集群服务(3)——集群功能详解
- Hazelcast集群服务(4)——分布式Map
Hazelcast 是一个开源的可嵌入式数据网格(社区版免费,企业版收费)。你可以把它看做是内存数据库,不过它与 Redis 等内存数据库又有些不同。项目地址:http://hazelcast.org/
Hazelcast 使得 Java 程序员更容易开发分布式计算系统,提供了很多 Java 接口的分布式实现,如:Map, Queue, Topic, ExecutorService, Lock, 以及 JCache 等。它以一个 JAR 包的形式提供服务,只依赖于 Java,并且提供 Java, C/C++, .NET 以及 REST 客户端,因此十分容易使用。
如何存储数据
Hazelcast 服务之间是端对端的,没有主从之分,因此也不存在单点故障。集群中所有的节点都存储等量的数据以及进行等量的计算。Hazelcast 缺省情况下把数据分为 271 个区。这个值可配置于系统属性
hazelcast.partition.count。 对于一个给定的键,在经过序列号、哈希并对分区总数取模之后能得到此键对应的分区号。所有的分区等量的分布与集群中所有的节点中,每个分区对应的备份也同样分布在集群中。下例是拥有2个节点的 Hazelcast 集群:
黑色字体表示分区,蓝色字体表示备份。节点1存储了1到135分区,这些分区同时备份在节点2中。节点2存储了136到271分区,并备份在节点1中。此时如果添加2个节点到集群中,Hazelcast 一个一个的移动分区和备份到新的节点,使得集群数据分布平衡。
注意实际中分区并不是有顺序的分布,而是随机分布,上面的示例只是为了方便理解。重要的是理解 Hazelcast 平均分布分区以及备份。Hazelcast 使用哈希算法进行数据分区。对于一个给定的键(如Map)或者对象名称(如topic和list):
- 序列化此键或对象名称,得到一个byte数组。
- 对byte数组进行哈希。
- 取模后的值即为分区号。
每个节点维护一个分区表,存储着分区号与节点之间的对应关系。这样每个节点都知道如何获取数据。
重分区
集群中最老的节点(或者说最先启动)负责定时发送分区表到其他节点。这样如果有节点加入或者离开集群,所有的节点也能更新分区表。注意: 如果最老的节点挂了,次老节点会接手这个任务。
这个定时任务时间间隔可配置系统属性
hazelcast.partition.table.send.interval。 缺省值为15秒。重分区发生在:
- 节点加入集群。
- 节点离开集群。
此时最老节点会更新分区表,分发,接着集群开始移动分区,或者从备份恢复分区。
使用方式
有两种方式:嵌入式和客户端服务器。
- 嵌入式,Hazelcast 服务器的 jar 包被导入宿主应用程序,服务器启动并存在于各个宿主应用中。优点是可以更低延迟的数据访问。
- 客户端服务器,Hazelcast 客户端的 jar 包被导入宿主应用程序,服务器 jar 包独立运行于 JVM 中。优点是更容易调试以及更可靠的性能,最重要的是更好的扩展性。
摘自: http://www.cnblogs.com/seasonsluo/p/hazelcast-intro.html以下是两段使用 Hazelcast 作为分布式 Map 和 Topic 的例子
1import com.hazelcast.config.Config;
2import com.hazelcast.core.Hazelcast;
3import com.hazelcast.core.HazelcastInstance;
4
5import java.util.concurrent.ConcurrentMap;
6
7public class DistributedMap {
8 public static void main(String[] args) {
9 Config config = new Config();
10 HazelcastInstance h = Hazelcast.newHazelcastInstance(config);
11 ConcurrentMap<String, String> map = h.getMap("my-distributed-map");
12 map.put("key", "value");
13
14 //Concurrent Map methods
15 map.putIfAbsent("somekey", "somevalue");
16 map.replace("key", "value", "newvalue");
17
18 map.forEach((k, v) -> System.out.println(k + " => " + v));
19
20 h.shutdown();
21 }
22} 1import com.hazelcast.config.Config;
2import com.hazelcast.core.*;
3
4public class DistributedTopic implements MessageListener<String> {
5
6 static HazelcastInstance h;
7
8 public static void main(String[] args) {
9 Config config = new Config();
10 h = Hazelcast.newHazelcastInstance(config);
11 ITopic<String> topic = h.getTopic("my-distributed-topic");
12 topic.addMessageListener(new DistributedTopic());
13 topic.publish("Hello to distributed world");
14 }
15
16 @Override
17 public void onMessage(Message<String> message) {
18 System.out.println("Got message " + message.getMessageObject());
19
20 h.shutdown();
21 }
22}启动后会看到输出
Members [2] {
Member [192.168.2.106]:5702 - 274180a0-f05e-467d-bd84-13249f9db491
Member [192.168.2.106]:5703 - 16de21f2-3c5c-477f-aec6-0a33d6d02aba this
}
即使是本地的启动方式也会打开 Socket 端口, 默认在本机启动两个不同的端口号. 其他 Hazelcast 的应用例子可参考 https://hazelcast.org/.
其他相关链接:
永久链接 https://yanbin.blog/hazelcast-introduction/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。