Java 与 Python 通过 Apache Avro 交换数据
最近转战到 Amazon 的云服务 AWS 上,考虑到在使用它的 Lambda 服务时 Python 应用有比较可观的启动速度,与之相比而言,Java 总是慢热型,还是一个内存大户。所以有想法 Lambda 函数用 Python 来写,来增强响应速度,而内部的应用仍然采用 Java, 于是就有了 Java 与 Python 的数据交换格式。使用 Kafka 的时候是用的 Apache Avro, 因此继续考察它。
注意,本文的内容会有很大部份与前一篇 Apache Avro 序列化与反序列化 (Java 实现) 雷同,不过再经一次的了应用,了解更深了。
在不同类型语言间进行数据交换,很容易会想到用 JSON 格式,那我们为什么还要用 Apache Avro 呢?通过接下来的内容,我们可以看到以下几点:
Apache Avro 官方提供有 C, C++, C#, Java, PHP, Python 和 Ruby 的支持库,可在网上找到其他语种的类库,如 NodeJS, Go 的,等等。
正所谓将要在 Java 和 Python 两个语言间用 Apache Avro 进行数据交换,所以后面的 Reader, Writer 代码会交错着进行
product.avsc 的内容也可以内联到 user.avsc 中,如果 product.avsc 需要被重用的话就最好用单独的文件定义。
上面的代码序列化了两个 User 实例,并写到了
执行后控制台下打印出
写到这里本想窥探一下 Apache Avro 的序列化数据格式,但一加就篇幅剧增,也超越了标题限定的范围,所以还是另立新篇。还是接着反着方向来看 Java 读取 Python 序列化的 Apache Avro 数据。
如果只是序列化 Product 的实例只需要用到
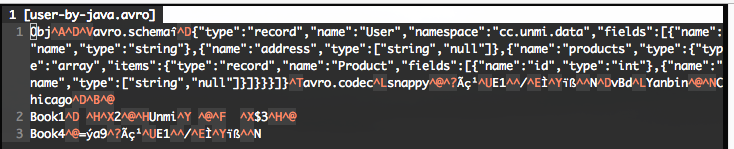 参考 Object Container Files, 简单说它的文件结构是 Magic(Obj+版本01), meta(avro.schema 和 avro.codec), sync(16字节的随机数), 最后加上数据。所以可以看出每次用这种结构来传送小对象是很不经济的,如果是直接用 JSON 或 JDK 序列化的话,只需要最后面数据部份,正如我们前面已看到和后面将要看到的代码一样,序列化文件中的非数据部分好像都是多余的。有效益的办法应该是让数据部分臃肿起来,挤兑掉非 Payload 部分所占的比例。
参考 Object Container Files, 简单说它的文件结构是 Magic(Obj+版本01), meta(avro.schema 和 avro.codec), sync(16字节的随机数), 最后加上数据。所以可以看出每次用这种结构来传送小对象是很不经济的,如果是直接用 JSON 或 JDK 序列化的话,只需要最后面数据部份,正如我们前面已看到和后面将要看到的代码一样,序列化文件中的非数据部分好像都是多余的。有效益的办法应该是让数据部分臃肿起来,挤兑掉非 Payload 部分所占的比例。
好啦,现在回过后来看 Java 的 reader 代码
类 Reader
读取代码总是比较简单的,可成功序列化为一个个 User 对象,执行后输出为
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
注意,本文的内容会有很大部份与前一篇 Apache Avro 序列化与反序列化 (Java 实现) 雷同,不过再经一次的了应用,了解更深了。
在不同类型语言间进行数据交换,很容易会想到用 JSON 格式,那我们为什么还要用 Apache Avro 呢?通过接下来的内容,我们可以看到以下几点:
- Apache Avro 序列化的格式也是 JSON 的,Java 的 Avro 库依赖于 Jackson 库
- 序列化数据库本身带有 Schema 定义的,方便于反序列化,特别是对于 Java 代码; 而 JavaScript 会表示多此一举
- 自动支持序列化数据的压缩,在官方提供的库中,Java 可支持
deflate,snappy,bzip2, 和xz. 其他语言中可能少些,如 Python 只支持deflate, 和snappy, 应该可扩充。序列化数据中 Schema 部分不被压缩 - 天然支持序列化对象列表,这样在序列化数据中只需要一份 Schema,类似于数据库表 Schema 加上多记录行的表示方式。只用 Apache Avro 传输小对象的话,数据量比 JSON 事 JDK 序列化的数据要大。
Apache Avro 官方提供有 C, C++, C#, Java, PHP, Python 和 Ruby 的支持库,可在网上找到其他语种的类库,如 NodeJS, Go 的,等等。
正所谓将要在 Java 和 Python 两个语言间用 Apache Avro 进行数据交换,所以后面的 Reader, Writer 代码会交错着进行
首先也是定义 Schema
与前篇略有不同的是,这里使用了两个 Schema 文件,其中的对象是一对多的关系文件 product.avsc
1{
2 "namespace": "cc.unmi.data",
3 "type": "record",
4 "name": "Product",
5 "fields": [
6 {"name": "id", "type": "int"},
7 {"name": "name", "type": ["string", "null"]}
8 ]
9}文件 user.avsc
1{
2 "namespace": "cc.unmi.data",
3 "type": "record",
4 "name": "User",
5 "fields": [
6 {"name": "name", "type": "string"},
7 {"name": "address", "type": ["string", "null"]},
8 {"name": "products", "type": {"type": "array", "items": "Product"}}
9 ]
10}product.avsc 的内容也可以内联到 user.avsc 中,如果 product.avsc 需要被重用的话就最好用单独的文件定义。
先看 Java 序列化,Python 反序列化
由 Schema 生成 Java 对象
Java 应用中我们一般会由前面的 Schema 定义生成 Java 领域对象,先要下载avro-tools-x.x.x.jar 工具包 ,然后执行java -jar avro-tools-1.8.1.jar compile schema product.avsc user.avsc java
User 和 Product 类将生成在 cc/unmi/data 目录中。生成的每一个 Java 对象中都含有当前的 Schema 定义,常量 SCHEMA$, 或可通过 getSchema() 方法来获得,所以对于 Java 的 Reader 都不需要依赖于序列化数据中的 Schema 定义。Java writer 的代码
我在项目中用的构建工具是 sbt, 所以引入 Apache Avro 的依赖方式如下libraryDependencies += "org.apache.avro" % "avro" % "1.8.1"
类 Writer
1package cc.unmi;
2
3import cc.unmi.data.Product;
4import cc.unmi.data.User;
5import org.apache.avro.file.CodecFactory;
6import org.apache.avro.file.DataFileWriter;
7import org.apache.avro.io.DatumWriter;
8import org.apache.avro.specific.SpecificDatumWriter;
9
10import java.io.File;
11import java.io.IOException;
12import java.util.Arrays;
13
14public class Writer {
15 public static void main(String[] args) throws IOException {
16
17 User user = User.newBuilder()
18 .setName("Yanbin")
19 .setAddress("Chicago")
20 .setProducts(Arrays.asList(
21 Product.newBuilder().setId(1).setName("Book1").build(),
22 Product.newBuilder().setId(2).setName("Book2").build()
23 )).build();
24
25 DatumWriter<User> userDatumWriter = new SpecificDatumWriter<>(User.class);
26 DataFileWriter<User> dataFileWriter = new DataFileWriter<>(userDatumWriter);
27 dataFileWriter.setCodec(CodecFactory.snappyCodec()); //采用 snappy 进行压缩
28 dataFileWriter.create(user.getSchema(), new File("../user-by-java.avro")); //序列化到文件中
29 dataFileWriter.append(user); //添加第一个实例
30
31 user.setName("Unmi");
32 user.getProducts().forEach(product -> {
33 product.setId(product.getId() + 2);
34 product.setName("Book" + (Integer.parseInt(product.getName().toString().substring(4)) + 2));
35 });
36 dataFileWriter.append(user); //添加第二个实例
37 dataFileWriter.close();
38 }
39}上面的代码序列化了两个 User 实例,并写到了
../user-by-java.avro 文件中, 数据部份用了 snappy 进行压缩。Python reader 代码
在 Python 开始应用 Apache Avro 之前,有几条命令要执行,假设是在 Mac 下brew install snappy # 在安装下一个之前一定要在系统中安装有 snappy 库Python 没有官方的由 Schema 文件生成 Python 类的工具,找到一个非官方的 avro-gen, 但用起来有问题。所以暂时忘了它,或者可以自己创建相关领域类。
pip install python-snappy # 让 Python 的 Avro 支持 snappy 压缩,否则只能用 deflate
pip install avro # 安装了 Python 的 Avro 库,也同时安装了 avro 命令,可以用 avro 命令读写数据
reader.py
1from avro.datafile import DataFileReader
2from avro.io import DatumReader
3
4reader = DataFileReader(open("../user-by-java.avro", "rb"), DatumReader())
5for user in reader:
6 print(user)
7reader.close()执行后控制台下打印出
{u'products': [{u'id': 1, u'name': u'Book1'}, {u'id': 2, u'name': u'Book2'}], u'name': u'Yanbin', u'address': u'Chicago'}在 Python 得到的是一个字典的列表,想要获得某个 user 的 name 属性要用
{u'products': [{u'id': 3, u'name': u'Book3'}, {u'id': 4, u'name': u'Book4'}], u'name': u'Unmi', u'address': u'Chicago'}
user['name'], 所以还是要创建出相应的类型用起来方便些。如果只是反序列化出字典的话,序列化数据中的 Schema 定义就毫无意义了。原生态的 JSON 对于 JavaScript 运用起来就得心应手了,怎么都是点操作,如 user.name。写到这里本想窥探一下 Apache Avro 的序列化数据格式,但一加就篇幅剧增,也超越了标题限定的范围,所以还是另立新篇。还是接着反着方向来看 Java 读取 Python 序列化的 Apache Avro 数据。
Python 序列化,Java 反序列化
Python writer 代码
由于未能生成相应的 Python 领域对象 Product 和 User, 所以在序列化时还需要获得 Schema 定义来指导工作,在本例中要序列化的数据是字典writer.py
1import avro.schema
2import json
3from avro.datafile import DataFileWriter
4from avro.io import DatumWriter
5
6# schema = avro.schema.parse(open("../user-with-product.avsc", "rb").read()) # 如果 product.avsc 内联在了 user.avsc 则只需这一句
7
8
9def load_avsc_files(*avsc_files):
10 all_schemas = avro.schema.Names()
11 schemas = None
12 for avsc_file in avsc_files:
13 file_text = open(avsc_file).read()
14 json_data = json.loads(file_text)
15 schemas = avro.schema.make_avsc_object(json_data, all_schemas)
16
17 # print json.dumps(user_schema.to_json(avro.schema.Names()), indent=2)
18
19 return schemas
20
21
22schema = load_avsc_files("../product.avsc", "../user.avsc") # 把多个 Schema 内联在一起
23
24writer = DataFileWriter(open("../user-by-python.avro", "w"), DatumWriter(), schema, codec="snappy")
25writer.append({'name': 'Yanbin', 'address': 'Chicago', 'products': [{'id': 3, 'name': 'Book3'}, {'id': 4, 'name': 'Book4'}]})
26writer.append({'name': 'Unmi', 'address': 'Chicago', 'products': [{'id': 4, 'name': 'Book4'}, {'id': 5, 'name': 'Book5'}]})
27writer.close()如果只是序列化 Product 的实例只需要用到
product.avsc 文件,最后序列化数据文件写在 ../user-by-python.avro 文件中,并且也采用了 snappy 来压缩数据。Java reader 代码
写到这里反而有些纳闷了,Apache Avro 与 JSON 的主要区别是它在序列化数据中自带 Schema 定义,而我们读写代码似乎只是把其中的 Schema 定义当摆设。由 Schema 生成的 Java 对象中已包含 Schema 定义,Python 把数据都当字典看待,更不关序列化数据中的 Schema 定义毛事。下图中生成的序列化文件数据
参考 Object Container Files, 简单说它的文件结构是 Magic(Obj+版本01), meta(avro.schema 和 avro.codec), sync(16字节的随机数), 最后加上数据。所以可以看出每次用这种结构来传送小对象是很不经济的,如果是直接用 JSON 或 JDK 序列化的话,只需要最后面数据部份,正如我们前面已看到和后面将要看到的代码一样,序列化文件中的非数据部分好像都是多余的。有效益的办法应该是让数据部分臃肿起来,挤兑掉非 Payload 部分所占的比例。好啦,现在回过后来看 Java 的 reader 代码
类 Reader
1package cc.unmi;
2
3import cc.unmi.data.User;
4import org.apache.avro.file.DataFileReader;
5import org.apache.avro.io.DatumReader;
6import org.apache.avro.specific.SpecificDatumReader;
7
8import java.io.File;
9import java.io.IOException;
10
11public class Reader {
12 public static void main(String[] args) throws IOException {
13 DatumReader<User> userDatumReader = new SpecificDatumReader<>();
14 DataFileReader<User> dataFileReader = new DataFileReader<>(new File("../user-by-python.avro"), userDatumReader);
15 dataFileReader.forEach(System.out::println);
16 }
17}读取代码总是比较简单的,可成功序列化为一个个 User 对象,执行后输出为
{"name": "Yanbin", "address": "Chicago", "products": [{"id": 3, "name": "Book3"}, {"id": 4, "name": "Book4"}]}本文示例代码请见 https://github.com/yabqiu/java-avro-python 永久链接 https://yanbin.blog/java-python-communicate-via-apache-avro/, 来自 隔叶黄莺 Yanbin's Blog
{"name": "Unmi", "address": "Chicago", "products": [{"id": 4, "name": "Book4"}, {"id": 5, "name": "Book5"}]}
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。