Lucene 应用 WordNet 的同义词典实现同义词检索(C#版)
同义词检索应该很多时候会用得上的,举个简单的例子,我们搜索关键字 good 的时候,与 well 和 fine 等的词条也可能是你想要的结果。这里我们不自己建立同义词库,直接使用 WordNet 的同义词库,本篇介绍 C# 版的实现步骤,还会有续篇--Java 版。
由于 Lucene 是发源于 Java,所以 C# 的应用者就没有 Java 的那么幸福了,Java 版已经有 3.0.2 可下载,C# 的版本还必须从 SVN 库里:https://svn.apache.org/repos/asf/lucene/lucene.net/tags/Lucene.Net_2_9_2/ 才能取到最新的 2.9.2 的源码,二制包还只有 2.0 的。
接下来就是用 VS 来编译它的,不多说。只是注意到在 contrib 目录中有 WordNet.Net 解决方案,这是我们想要的,编译 WordNet.Net 可得到三个可执行文件:
1. Syns2Index.exe 用来根据 WordNet 的同义词库建立同义词索引文件,同义词本身也是通过 Lucene 来查询到的
2. SynLookup.exe 从同义词索引中查找某个词有哪些同义词
3. SynExpand.exe 与 SynLookup 差不多,只是多了个权重值,大概就是同义程度
好啦,有了 Lucene.Net.dll 和上面那三个文件,我们下面来说进一步的步骤:
二. 下载 WordNet 的同义词库
可以从 http://wordnetcode.princeton.edu/3.0/ 下载 WNprolog-3.0.tar.gz 文件。然后解压到某个目录,如 D:\WNprolog-3.0,其中子目录 prolog 中有许多的 pl 文件,下面要用到的就是 wn_s.pl
三. 生成同义词 Lucene 索引
使用命令
Syns2Index.exe d:\WNprolog-3.0\prolog\wn_s.pl syn_index
第二个参数是生成索引的目录,由它来帮你创建该目录,执行时间大约 40 秒。这是顺利的时候,也许你也会根本无法成功,执行 Syns2Index.exe 的时候出现下面的错误:
writer.SetMaxBufferedDocs(writer.GetMaxBufferedDocs() * 2*/); //GetMaxBufferedDocs() 本身就为 0,翻多少倍也是白搭
因为
writer.SetMaxBufferedDocs(100); //所以直接改为 100 或大于 2 的数就行
重新使用新编译的 Syns2Index.exe 执行上一条命令即可。成功执行后,可以看到新生成了一个索引目录 syn_index, 约 3 M。
现在可以用另两个命令来测试一下索引文件:
四. 使用同义词分析器、过滤器进行检索
相比,Java 程序员要轻松许多,有现成的 lucene-wordnet-3.0.2.jar,里面有一些现在的代码可以用。C# 的那些分析器和过滤器就得自己写了,或许我已走入了一个岔道,但也不算崎岖。
小步骤就不具体描述了,直接上代码,大家从代码中去理解:
同义词引擎接口
同义词引擎实现类
过滤器,下面的分析器要用到
分析器,使用了多个过滤器,当然最主要是用到了上面定义的同义词过滤器
最后,当然是要应用上面的同义词引擎和过滤器,分析器了
五. 看看同义词检索的效果
看前面一大面,也不知道有几人能到达这里,该感性的认识一下,上图看真相:
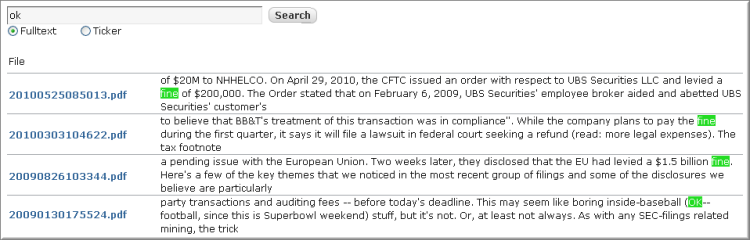
搜索 ok,由于 fine 是 ok 的同义词,所以也被检索到,要有其他同义的结果也能显示出来的。
参考:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
由于 Lucene 是发源于 Java,所以 C# 的应用者就没有 Java 的那么幸福了,Java 版已经有 3.0.2 可下载,C# 的版本还必须从 SVN 库里:https://svn.apache.org/repos/asf/lucene/lucene.net/tags/Lucene.Net_2_9_2/ 才能取到最新的 2.9.2 的源码,二制包还只有 2.0 的。
接下来就是用 VS 来编译它的,不多说。只是注意到在 contrib 目录中有 WordNet.Net 解决方案,这是我们想要的,编译 WordNet.Net 可得到三个可执行文件:
1. Syns2Index.exe 用来根据 WordNet 的同义词库建立同义词索引文件,同义词本身也是通过 Lucene 来查询到的
2. SynLookup.exe 从同义词索引中查找某个词有哪些同义词
3. SynExpand.exe 与 SynLookup 差不多,只是多了个权重值,大概就是同义程度
好啦,有了 Lucene.Net.dll 和上面那三个文件,我们下面来说进一步的步骤:
二. 下载 WordNet 的同义词库
可以从 http://wordnetcode.princeton.edu/3.0/ 下载 WNprolog-3.0.tar.gz 文件。然后解压到某个目录,如 D:\WNprolog-3.0,其中子目录 prolog 中有许多的 pl 文件,下面要用到的就是 wn_s.pl
三. 生成同义词 Lucene 索引
使用命令
Syns2Index.exe d:\WNprolog-3.0\prolog\wn_s.pl syn_index
第二个参数是生成索引的目录,由它来帮你创建该目录,执行时间大约 40 秒。这是顺利的时候,也许你也会根本无法成功,执行 Syns2Index.exe 的时候出现下面的错误:
Unhandled Exception: System.ArgumentException: maxBufferedDocs must at least be 2 when enabled莫急,手中有源码,心里不用慌,只要找到 Syns2Index 工程,改动 Syns2Index.cs 文件中的
at Lucene.Net.Index.IndexWriter.SetMaxBufferedDocs(Int32 maxBufferedDocs)
at WorldNet.Net.Syns2Index.Index(String indexDir, IDictionary word2Nums, IDictionary num2Words)
at WorldNet.Net.Syns2Index.Main(String[] args)
writer.SetMaxBufferedDocs(writer.GetMaxBufferedDocs() * 2*/); //GetMaxBufferedDocs() 本身就为 0,翻多少倍也是白搭
因为
writer.SetMaxBufferedDocs(100); //所以直接改为 100 或大于 2 的数就行
重新使用新编译的 Syns2Index.exe 执行上一条命令即可。成功执行后,可以看到新生成了一个索引目录 syn_index, 约 3 M。
现在可以用另两个命令来测试一下索引文件:
D:\wordnet>SynLookup.exe syn_index hi也可以用 Luke - Lucene Index ToolBox 来查看索引,两个字段,syn 和 word,通过 word:hi 就可以搜索到 syn:hawaii hello howdy hullo
Synonyms found for "hi":
hawaii
hello
howdy
hullo D:\wordnet>SynExpand.exe syn_index hi
Query: hi hawaii^0.9 hello^0.9 howdy^0.9 hullo^0.9
四. 使用同义词分析器、过滤器进行检索
相比,Java 程序员要轻松许多,有现成的 lucene-wordnet-3.0.2.jar,里面有一些现在的代码可以用。C# 的那些分析器和过滤器就得自己写了,或许我已走入了一个岔道,但也不算崎岖。
小步骤就不具体描述了,直接上代码,大家从代码中去理解:
同义词引擎接口
1using System.Collections.Generic;
2
3namespace Com.Unmi.Searching
4{
5 /// <summary>
6 /// Summary description for ISynonymEngine
7 /// </summary>
8 public interface ISynonymEngine
9 {
10 IEnumerable<string> GetSynonyms(string word);
11 }
12}同义词引擎实现类
1using System.IO;
2using System.Collections.Generic;
3using Lucene.Net.Analysis;
4using Lucene.Net.Analysis.Standard;
5using Lucene.Net.Documents;
6using Lucene.Net.QueryParsers;
7using Lucene.Net.Search;
8using Lucene.Net.Store;
9
10using LuceneDirectory = Lucene.Net.Store.Directory;
11using Version = Lucene.Net.Util.Version;
12
13namespace Com.Unmi.Searching
14{
15 /// <summary>
16 /// Summary description for WordNetSynonymEngine
17 /// </summary>
18 public class WordNetSynonymEngine : ISynonymEngine
19 {
20
21 private IndexSearcher searcher;
22 private Analyzer analyzer = new StandardAnalyzer();
23
24 //syn_index_directory 为前面用 Syns2Index 生成的同义词索引目录
25 public WordNetSynonymEngine(string syn_index_directory)
26 {
27
28 LuceneDirectory indexDir = FSDirectory.Open(new DirectoryInfo(syn_index_directory));
29 searcher = new IndexSearcher(indexDir, true);
30 }
31
32 public IEnumerable<string> GetSynonyms(string word)
33 {
34 QueryParser parser = new QueryParser(Version.LUCENE_29, "word", analyzer);
35 Query query = parser.Parse(word);
36 Hits hits = searcher.Search(query);
37
38 //this will contain a list, of lists of words that go together
39 List<string> Synonyms = new List<string>();
40
41 for (int i = 0; i < hits.Length(); i++)
42 {
43 Field[] fields = hits.Doc(i).GetFields("syn");
44 foreach (Field field in fields)
45 {
46 Synonyms.Add(field.StringValue());
47 }
48 }
49
50 return Synonyms;
51 }
52 }
53}过滤器,下面的分析器要用到
1using System;
2using System.Collections.Generic;
3using Lucene.Net.Analysis;
4
5namespace Com.Unmi.Searching
6{
7 /// <summary>
8 /// Summary description for SynonymFilter
9 /// </summary>
10 public class SynonymFilter : TokenFilter
11 {
12 private Queue<Token> synonymTokenQueue = new Queue<Token>();
13
14 public ISynonymEngine SynonymEngine { get; private set; }
15
16 public SynonymFilter(TokenStream input, ISynonymEngine synonymEngine)
17 : base(input)
18 {
19 if (synonymEngine == null)
20 throw new ArgumentNullException("synonymEngine");
21
22 SynonymEngine = synonymEngine;
23 }
24
25 public override Token Next()
26 {
27 // if our synonymTokens queue contains any tokens, return the next one.
28 if (synonymTokenQueue.Count > 0)
29 {
30 return synonymTokenQueue.Dequeue();
31 }
32
33 //get the next token from the input stream
34 Token token = input.Next();
35
36 //if the token is null, then it is the end of stream, so return null
37 if (token == null)
38 return null;
39
40 //retrieve the synonyms
41 IEnumerable<string> synonyms = SynonymEngine.GetSynonyms(token.TermText());
42
43 //if we don't have any synonyms just return the token
44 if (synonyms == null)
45 {
46 return token;
47 }
48
49 //if we do have synonyms, add them to the synonymQueue,
50 // and then return the original token
51 foreach (string syn in synonyms)
52 {
53 //make sure we don't add the same word
54 if (!token.TermText().Equals(syn))
55 {
56 //create the synonymToken
57 Token synToken = new Token(syn, token.StartOffset(),
58 t.EndOffset(), "<SYNONYM>");
59
60 // set the position increment to zero
61 // this tells lucene the synonym is
62 // in the exact same location as the originating word
63 synToken.SetPositionIncrement(0);
64
65 //add the synToken to the synonyms queue
66 synonymTokenQueue.Enqueue(synToken);
67 }
68 }
69
70 //after adding the syn to the queue, return the original token
71 return token;
72 }
73 }
74}分析器,使用了多个过滤器,当然最主要是用到了上面定义的同义词过滤器
1using Lucene.Net.Analysis;
2using Lucene.Net.Analysis.Standard;
3
4namespace Com.Unmi.Searching
5{
6 public class SynonymAnalyzer : Analyzer
7 {
8 public ISynonymEngine SynonymEngine { get; private set; }
9
10 public SynonymAnalyzer(ISynonymEngine engine)
11 {
12 SynonymEngine = engine;
13 }
14
15 public override TokenStream TokenStream(string fieldName, System.IO.TextReader reader)
16 {
17 //create the tokenizer
18 TokenStream result = new StandardTokenizer(reader);
19
20 //add in filters
21 // first normalize the StandardTokenizer
22 result = new StandardFilter(result);
23
24 // makes sure everything is lower case
25 result = new LowerCaseFilter(result);
26
27 // use the default list of Stop Words, provided by the StopAnalyzer class.
28 result = new StopFilter(result, StopAnalyzer.ENGLISH_STOP_WORDS);
29
30 // injects the synonyms.
31 result = new SynonymFilter(result, SynonymEngine);
32
33 //return the built token stream.
34 return result;
35 }
36 }
37}最后,当然是要应用上面的同义词引擎和过滤器,分析器了
1using System.IO;
2using System.Web;
3using Lucene.Net.Index;
4using System;
5using Lucene.Net.Analysis.Standard;
6using Lucene.Net.Documents;
7using System.Collections.Generic;
8using Lucene.Net.Analysis;
9using Lucene.Net.Search;
10using Lucene.Net.QueryParsers;
11using Lucene.Net.Store;
12using Version = Lucene.Net.Util.Version;
13using System.Collections;
14using Lucene.Net.Highlight;
15
16using LuceneDirectory = Lucene.Net.Store.Directory;
17
18namespace Com.Unmi.Searching
19{
20 public class Searcher
21 {
22 /// <summary>
23 /// 假定前面创建的同义词索引目录是 d:\indexes\syn_index,
24 /// 要搜索的内容索引目录是 d:\indexes\file_index, 且索引中有两字段 file 和 content
25 /// IndexEntry 是你自己创建的一个搜索结果类,有两属性 file 和 fragment
26 /// </summary>
27 /// <param name="querystring">queryString</param>
28 public static List<IndexEntry> Search(queryString)
29 {
30 //Now SynonymAnalyzer
31 ISynonymEngine synonymEngine = new WordNetSynonymEngine(@"d:\indexes\syn_index");
32 Analyzer analyzer = new SynonymAnalyzer(synonymEngine);
33
34 LuceneDirectory indexDir = FSDirectory.Open(new DirectoryInfo(@"d:\indexes\file_index");
35 IndexSearcher searcher = new IndexSearcher(indexDir, true);
36
37 QueryParser parser = new QueryParser(Version.LUCENE_29,"content", analyzer);
38
39 Query query = parser.Parse(queryString);
40
41 Hits hits = searcher.Search(query);
42
43 //返回类型是一个 IndexEntry 列表,它有两个属性 file 和 fragment
44 List<IndexEntry> entries = new List<IndexEntry>();
45
46 //这里还用到了 Contrib 里的另一个 Lucene 辅助组件,高亮显示搜索关键字
47 SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='background-color:#23dc23;color:white'>", "</span>");
48 Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
49
50 highlighter.SetTextFragmenter(new SimpleFragmenter(256));
51 highlighter.SetMaxDocBytesToAnalyze(int.MaxValue);
52
53 Analyzer standAnalyzer = new StandardAnalyzer();
54
55 for (int i = 0; i < hits.Length(); i++)
56 {
57 Document doc = hits.Doc(i);
58
59 //Any time, can't use the SynonymAnalyzer here
60 //注意,这里不能用前面的 SynonymAnalyzer 实例,否则将会陷入一系列可怕的循环
61 string fragment = highlighter.GetBestFragment(standAnalyzer/*analyzer*/, "content", doc.Get("content"));
62
63 IndexEntry entry = new IndexEntry(doc.Get("file"), fragment);
64 entries.Add(entry);
65 }
66
67 return entries;
68 }
69 }
70}五. 看看同义词检索的效果
看前面一大面,也不知道有几人能到达这里,该感性的认识一下,上图看真相:
搜索 ok,由于 fine 是 ok 的同义词,所以也被检索到,要有其他同义的结果也能显示出来的。
参考:
- e-使用sandbox的wordnet完成同义词索引
- http://www.chencer.com/techno/java/lucene/wordnet.html
- lucene connector » org.apache.lucene.wordnet
- Lucene.Net – Custom Synonym Analyzer(本文比较多的参考这篇)
- Lucene in action 笔记 analysis篇
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。