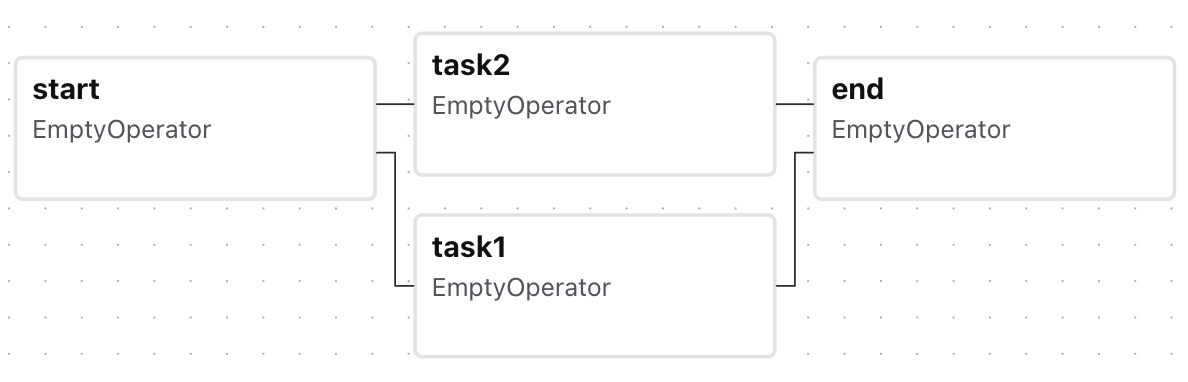
来到稍微复杂一点的流程,虽说 DAG 不能有循环但分支还是可以有的。比如下面的分支流程
来到稍微复杂一点的流程,虽说 DAG 不能有循环但分支还是可以有的。比如下面的分支流程start >> [task1, task2] >> end
在 Airflow UI 中展示出来就是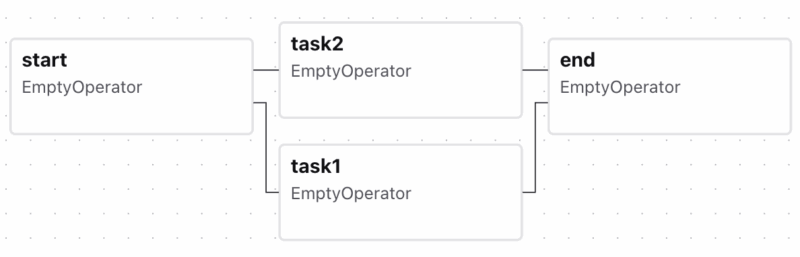 Airflow 默认下游 Task 的
Airflow 默认下游 Task 的 trigger_rule是all_success, 即要求上游的所有 Task 都必须成功才会执行,否则跟随着失败或跳过,这对于并行处理然后汇集结果的应用是合理的。
本文将要使用到的是分支(BranchPythonOperator), 比如共用一个 DAG, 周中与周末执行不同的分支,或根据条件从不同的数据源采集数据,下流的任务则需在任何一个分支成功即可触发。对上面的流程加上辅助任务,使其表达性更强 Read More 使用 Tomcat 时应根据服务器的负载和客户端能接受的等待情可适当的调节 maxThreads, acceptCount, maxConnections 的值。这三个参数只有 maxThreads 是最容易理解,即 Tomcat 当前最大同时处理请求的数目,其他两个参数有些模糊。而搜索网络相关的解释发现一些相互矛盾的地方,本文将通过调整这几个值,实际体验它们对请求连接的影响。
使用 Tomcat 时应根据服务器的负载和客户端能接受的等待情可适当的调节 maxThreads, acceptCount, maxConnections 的值。这三个参数只有 maxThreads 是最容易理解,即 Tomcat 当前最大同时处理请求的数目,其他两个参数有些模糊。而搜索网络相关的解释发现一些相互矛盾的地方,本文将通过调整这几个值,实际体验它们对请求连接的影响。
在测试之前,先看看 Tomcat 官网的解释,你可能不信 AI 的胡说八道,官网仍然是最可信的。在关于 The HTTP Connector 一章中,找到它们三者之间的说明原文是Each incoming, non-asynchronous request requires a thread for the duration of that request. If more simultaneous requests are received than can be handled by the currently available request processing threads, additional threads will be created up to the configured maximum (the value of the
用 Google 翻译后 Read MoremaxThreadsattribute). If still more simultaneous requests are received, Tomcat will accept new connections until the current number of connections reachesmaxConnections. Connections are queued inside the server socket created by the Connector until a thread becomes available to process the connection. OncemaxConnectionshas been reached the operating system will queue further connections. The size of the operating system provided connection queue may be controlled by theacceptCountattribute. If the operating system queue fills, further connection requests may be refused or may time out.- 继续玩弄那个小风车,先前买的 《Data Pipelines with Apache Airflow》 一眼没看直接作废,因为是基于 Apache Airflow 2.x 的,3.0 既出立马又买了该书的第二版,倒是基于 Apache Airflow 3.0 的,但写书之时 3.0 尚未正式推出,所以书中内容与实际应用有许多出入。
Apache Airflow 自 2.4 起就支持基于 Asset 事件触发 DAG,那时叫做 Data-aware,从 Apache Airflow 3.0 起更名为 Asset-Aware, 并且在 UI 上也会显示使用到的 Assets。那么 Asset-Aware 解决什么问题呢,它采用了 Producer/Consumer 模式可把依赖的某一共同资源的 DAG 串联起来。比如某一个 Producer DAG 写了文件到 s3://asset-bucket/example.csv, (发布一个事件 ), 然后相当于订阅了该事件所有相关 Consumer DAG 都会得到执行。
Airflow 的 Asset 使用 URI 的格式- s3://asset-bucket/example.csv
- file://tmp/data/export.json
- postgresql://mydb/schema/mytable
- gs://my-bucket/processed/report.parquet
- 本文大概记录一下在 Apache Airflow 的 Task 或 Operator(这两个基本是同一概念) 中如何使用 模板(Template) 和上下文(Context). Airflow 的模板引擎用的 Jinja Template, 它也被 FastAPI 和 Flask 所采纳。首先只有构造 Operator 时的参数或参数指定的文件内容中,或者调用 Operator render_template() 方法才能用模板语法,像
{{ ds }}. Apache Airflow 有哪些模板变量可用请参考: Templates references / Variables, 本文将会打印出一个 Task 的 context 变量列出所有可用的上下文变量, 不断的深入,最后在源代码找到相关的定义。
通过使用模板或上下文,我们能能够在任务中使用到 Apache Airflow 一些内置的变量值,如 DAG 或任务当前运行时的状态等 。
当我们手动触发一个 DAG 时, 在Configuration JSON中输入的参数也能在 context 中找到. 所有的 Operator 继承链可追溯到 AbstractOperator -> Templater, 因此所有的 Operator(Task) 都能通过调用 Templater.render_template() 方法对模板进行渲染,该方法的原型是 Read More - Apache Airflow 重新唤起我的注意力是因为 Airflow 3.0 在近日 April 22, 2025 发布了,其二则是我们一直都有计划任务的需求,以下几种方案都太简陋
- 用 Windows 的计划任务或 Linux 的 Cron 都不易管理,且有单点故障问题
- 在 Java Spring 项目中使用集群模式的 Quartz 有些麻烦,且对于 AutoScaling 也不怎么友好
- AWS 上用 CloudWatch Rule + AWS Lambda 的方案可靠性没有问题,但不适于监控
因此还有必要再次尝试 Apache Airflow, 它有集中管理的界面,各个部件都是可伸缩的,如 WebServer, Workers 等。特别是刚出的 Apache Airflow 3.0 带来以下主要新特性- 新的服务化架构,各个部件间耦合度降低
- 多语言支持,借助了 Task SDK, 可望用 Java, JavaScript, TypeScript 等语言写 DAG
- DAG 支持版本控制,可回溯历史
- 支持事件驱动,即 DAG 可响应外部事件,如文件到达,消息队列等
- 引入了资产驱动调度功能,可根据数据资产的变化 进行触发,可以说是事件驱动的一类
- 全新的 React UI 界面
Read More  早先对 Java ArrayList 的扩容理解是在 new ArrayList() 时会默认建立一个内部容量为 16(这个数值还是错的,往后看) 大小的数组,然而插入数据容量不足时会扩容为原来的 1.5 倍,并用 System.arraycopy() 移动原来的数组到新的大数组中,所以为了频繁的内部扩容操作,在已知 ArrayList 将来大小的情况下,应该在创建 ArrayList 时指定大小,如 new ArrayList(1000)。那么是否指定初始容量对性能会有多大的影响仍缺乏感性的认识。
早先对 Java ArrayList 的扩容理解是在 new ArrayList() 时会默认建立一个内部容量为 16(这个数值还是错的,往后看) 大小的数组,然而插入数据容量不足时会扩容为原来的 1.5 倍,并用 System.arraycopy() 移动原来的数组到新的大数组中,所以为了频繁的内部扩容操作,在已知 ArrayList 将来大小的情况下,应该在创建 ArrayList 时指定大小,如 new ArrayList(1000)。那么是否指定初始容量对性能会有多大的影响仍缺乏感性的认识。
本文通过具体的测试主要掌握以下知识- new ArrayList() 默认容量大小(JDK 8 以前是 10, JDK 8 及以后为 0)
- ArrayList 何时进行扩容,以及每次扩容多少
- new ArrayList() 时是否指定初始容量值的性能对比
- 除了 ArrayList 自动扩容外,它会不会自动缩容呢?
new ArrayList() 的默认容量多少及增容策略
就像 JDK 8 的 HashMap 引入了红黑树改善性,随着 JDK 版本的升级 ArrayList 的内部实现也在演进。回到 JDK 7, 当我们不指定容量 new ArrayList() 创建一个对象时的实现是 Read More- Java 代码中如果显式的用
throw关键字抛出异常,那么在该分支中其后的语句不可到达,并且即使对于有返回值的函数也不必写return语句了。像下面的代码1private static int foo(int num) { 2 if (num == 0) { 3 throw new RuntimeException(""); 4 } else { 5 return num + 1; 6 } 7}
以上代码是合法的。要清洁代码的话,最后的return num + 1不必写在else条件中,这样写只是为了验证抛出异常后不必有返回值。
比如我们想对该代码进行重构,把throw语句抽取到一个方法中,以便于在该方法中集中处理错误信息,于是变成了 Read More  不得不承认因为 ChatGPT 为代表的 AI 的出现,让许多技术博客的写作者积极性大大降低。但本着以学习掌握知识为目的,实战,写下来对加强学习仍然是非常有意义的。如果一直使用 AI 来解决技术问题,知识永远是 AI 的,至于说有了 AI 本应没有主动学习必要的性的话,永远保持像一张白纸,A4 大小,那真就无话可说了。
不得不承认因为 ChatGPT 为代表的 AI 的出现,让许多技术博客的写作者积极性大大降低。但本着以学习掌握知识为目的,实战,写下来对加强学习仍然是非常有意义的。如果一直使用 AI 来解决技术问题,知识永远是 AI 的,至于说有了 AI 本应没有主动学习必要的性的话,永远保持像一张白纸,A4 大小,那真就无话可说了。
开发过程驱动有分 TDD(Test-Driven Development) 和 BDD(Behavior-Driven Development),大致的理解是 TDD 更关注实现细节,BDD 更接近于 QA 的测试,对领域的测试。BDD 从抽象中来讲更适于做面向用户的集成测试。当然在 AI 生成代码的年代可能单玩测试反而不那么重要,因为更多是一次性代码。
BDD 给人最典型的印象是 Scenario/Given/When/Then, BDD 最流行的测试框架当属 Cucumber, 它以插件的方式支持众多编程语方,如官方支持的用 JavaScript, Java, Kotlin, Ruby, Lua, Scala, C++, Go, OCaml, 还有其他半官支持的 Python, Swift/ObjC, Perl, .NET(C#, F#, VB), 以及非官方支持的 Rust, D, Groovy 等。
另外还有一个专供 Java 的轻量级 JBehave, 不过个人更推荐用 Cucumber, 因为 Cucumber 得到更多 IDE 如 IntelliJ, Eclipse, VS Code 等的支持,并能与 JUnit 4, JUnit 5, TestNG, 以及 Spring Boot 项目集成,内置的测试报告插件,多语言当然是个亮点。
本文主要关注 Maven 项目中如何使用 Cucumber, 循序渐进的从简单的测试开始,然后跃进到与 JUnit 5/ JUnit 4 的结合,以及普通 Unit Test 和 BDD 测试如何并存且可区分的执行,或者在 Maven 中创建独立的 src/bdd 目录单独存放 BDD 测试用例。 Read More FastAPI 比起 Flask 而言一个十分便利的功能是它内置对 Swagger UI 文档的支持,然而默认生成的 Swagger UI 也总不尽如人意,于是就有了如何通过引入自己的样式(或样式文件)对默认 Swagger UI 进行定制化的需求。在 ChatGPT 之前,Google 和阅读源代码是齐头并进的选择,自己有了 ChatGPT 之类的 AI, 人们一下就把身段放低了许多,再也不像使用 Google 那样的心态去使用 AI 了。所以呢,第一次支持付了 $8 问问当前号称最厉害的 Grok 3(也算是对 DOGE 的支持吧), 得到答案如下
FastAPI 比起 Flask 而言一个十分便利的功能是它内置对 Swagger UI 文档的支持,然而默认生成的 Swagger UI 也总不尽如人意,于是就有了如何通过引入自己的样式(或样式文件)对默认 Swagger UI 进行定制化的需求。在 ChatGPT 之前,Google 和阅读源代码是齐头并进的选择,自己有了 ChatGPT 之类的 AI, 人们一下就把身段放低了许多,再也不像使用 Google 那样的心态去使用 AI 了。所以呢,第一次支持付了 $8 问问当前号称最厉害的 Grok 3(也算是对 DOGE 的支持吧), 得到答案如下1app.mount("/static", StaticFiles(directory="static"), name="static")<br/><br/> 2app = FastAPI( 3 swagger_ui_parameters={ 4 "css_url": "/static/custom_swagger.css" 5 } 6)
在网站的 /static 目录下也创建了 custom_swagger.css 文件,然而根本就没有效果,Inspect 浏览器后发现 FastAPI 的 /docs 根本就有加载 /static/custom_swagger.css 文件。 Read More