Python 3.7 所带来的新特性
Python 接触的晚,所以接着 体验一下 Python 3.8 带来的主要新特性 继续往前翻,体验一下 Python 3.7 曾经引入的新特性,爱一门语言就要了解她真正的历史。一步一步慢慢给 Python 来个起底。
先来看看 Python 网站的各版本使用情况 Usage statistics of Python Version 3 for websites, 这里统计的 Python 开发的网站的数据,应该有 Python 3 大规模的用于其他领域。单网站应用 Python 来说,Python 2 还有大量遗留代码,Python 3 还是 3.6 为主,Python 的升级还任重道远。本人也是谨慎的在从 3.7 迁移到 3.8 的过程中,AWS 的 Lambda 都支持 3.8,直接上 3.8 也没什么历史负担。以下是从网站使用 Python 统计情况中的两个截图
Python 3.7.0 发布于 2018-06-27, 这篇文章 Cool New Features in Python 3.7 详细介绍了 Python 3.7 的新特性,本文也是从其中挑几个来体验体验。
这个功能好像没什么卵用,现在随手一个 IDE 都能断点调试,大不了临时加些
用 python 3.7 bug.py 执行,然后看到
参考 PDB 的用法,比如输入变量名可以查看它的值,
如果要跳过代码中的所有
是不是没多大可能用得上它啊。
上面创建了一个 Country 数据类,我们需要指定每个字段的类型,或默认值或其他的描述,Python 会把字段收集起来生成一个构建函数
用
我们曾经需要用
但是有一点缺憾是 Python 的数据类不能直接被 json 序列化,
在解析构造函数的时候认为
 Python 3.7 中其实也不必要写成
Python 3.7 中其实也不必要写成
上面的代码顺利通过,加上
再一个例子,类型提示不光是类型,字符串描述,还可以是一条语句,如
因为
同样的,引入
根本就不对
Python 的类型提示还可以更复杂,而且 IDE 还能推算出它的实际的提示类型,看 PyCharm 中的提示
我们多数时候不应该依赖于字典的顺序的,这一特性可以想像是相当于由
Python 3.5 开始引入了
在 Python 3.7 之前支持协程要显示的使用事件循环,比如使用如下代码
Python 3.7 开始有了
这里的
为了更好理解,需要放到多线程环境中去演示它,用下面的
10 个任务重用三个线程,发现
第二段代码,演示了如何应用指定的上下文变量去运行代码
执行效果如下:
总体说来没多大的惊喜,毕竟是一个小版本的更新,想要惊喜的话得看 Python 3.0 的 What's New。如果这以上新特性较为有用的也就 数据类 和 上下文变量,但由于数据类不能被 JSON 序列化,在用作 Rest API 时还得转换为字典再序列化为 JSON。 永久链接 https://yanbin.blog/python-3-7-what-is-new/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
先来看看 Python 网站的各版本使用情况 Usage statistics of Python Version 3 for websites, 这里统计的 Python 开发的网站的数据,应该有 Python 3 大规模的用于其他领域。单网站应用 Python 来说,Python 2 还有大量遗留代码,Python 3 还是 3.6 为主,Python 的升级还任重道远。本人也是谨慎的在从 3.7 迁移到 3.8 的过程中,AWS 的 Lambda 都支持 3.8,直接上 3.8 也没什么历史负担。以下是从网站使用 Python 统计情况中的两个截图
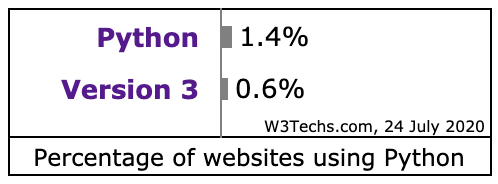
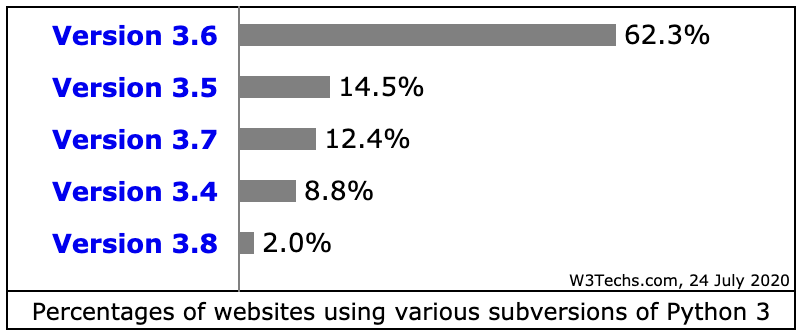 |
breakpoint() 进入调试器
这个功能好像没什么卵用,现在随手一个 IDE 都能断点调试,大不了临时加些 print 语句,把 breakpoint() 语句留在代码中也是个垃圾。不管它呢,既然是个新特性,顺道看下了,就是说在代码中加行 breakpoint(),代码执行到该处就会默认进入 PDB(Python Debugger) 调用会话。1# bug.py
2e = 1
3f = 2
4breakpoint()
5r = e / f
6print(r)1$ python3.7 bug.py
2> /Users/yanbin/bug.py(4)<module>()
3-> r = e / f
4(Pdb) e
51
6(Pdb) c
70.5c 继续执行。breakpoint() 是之前的 import pdb; pdb.set_trace() 的缩减写法。如果要跳过代码中的所有
breakpoint() 停顿,可设置 PYTHONBREAKPOINT=01$ PYTHONBREAKPOINT=0 python3.7 bug.py
20.5数据类
这可是个大趋势,像在 Java 中Playframwork 曾给 public 属性自动生成 getter/setter 方法,还有用 Lombok 来辅助的,直到 Java 14 出现了 record 类,Scala 的 case class,Kotlin 中也有 data class 类型 -- 一枚典型的 Javaer。所以 Python 也有了类似的实现,@dataclass 让我们从 __init__ 构造函数中一个个写 self.field_name = field_name 中挣脱出来,并且会自动生成一些其他的双下划线方法。 1from dataclasses import dataclass, field
2
3@dataclass(order=True)
4class Country:
5 name: str
6 population: int
7 area: float = field(repr=False, compare=False)
8 coastline: float = 0
9
10 def other_method(self):
11 pass1class Country:
2
3 def __init__(self, name, population, area, coastline=0):
4 self.name = name
5 self.population = population
6 self.area = area
7 self.coastline = coastline
8
9......c.name 来访问属性,同时它还为我们生成了诸如 __repr__, __eq__, __ne__, __lt__, __le__, __gt__, __ge__ 实现方法我们曾经需要用
collections.namedtuple 来实现类似的行为。这里有一个关于 dataclass 详细的介绍 The Ultimate Guide to Data Classes in Python 3.7。但是有一点缺憾是 Python 的数据类不能直接被 json 序列化,
json.dumps(c) 会得到错误:TypeError: Object of type Country is not JSON serializable。类型提示强化和延迟注解求值
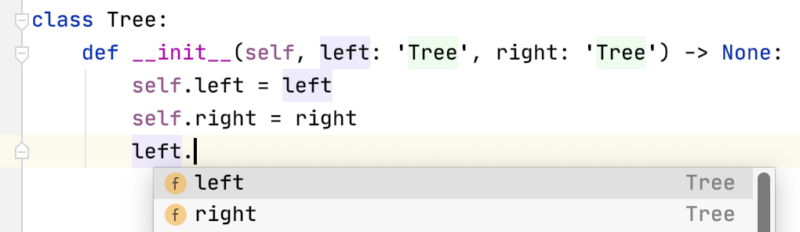
Python 3.5 开始引入了类型提示,Python 在这方面还在不断的演化,Python 3.7 中下面的代码不能通过1class Tree:
2 def __init__(self, left: Tree, right: Tree) -> None:
3 self.left = left
4 self.right = rightTree 类型还没有正式建立起来,提示错误NameError: name 'Tree' is not defined只有给类型提示用引号括起来,把它们当字符串来看待就行,在 IDE 中还不引影响代码提示
 Python 3.7 中其实也不必要写成
Python 3.7 中其实也不必要写成 left: 'Tree', 加上 from __future__ import annotations 就行1from __future__ import annotations
2
3class Tree:
4 def __init__(self, left: Tree, right: Tree) -> None:
5 self.left = left
6 self.right = rightfrom __future__ import annotations 就是让 left: Tree 类型提示能延迟求值再一个例子,类型提示不光是类型,字符串描述,还可以是一条语句,如
1# anno.py
2def greet(name: print("Now!")):
3 print(f"Hello {name}")name: print("Now!") 这样的类型提示会在解释该方法放入命名空间的时候求值,即 import 就会打印出信息1>>> import anno
2Now!
3>>> anno.greet.__annotations__
4{'name': None}print("Now!") 的返回值为 None, 提示的 name 类型也就为 None同样的,引入
from __future__ import annotations 还能禁止 print("Now!") 的求值,anno.py 的内容如下1from __future__ import annotations<br/><br/>
2def greet(name: print("Now!")):
3 print(f"Hello {name}")- 再到 Python REPL 中试下
1>>> import anno
2>>> anno.greet.__annotations__
3{'name': "print('Now!')"}
4>>> anno.greet("Marty")
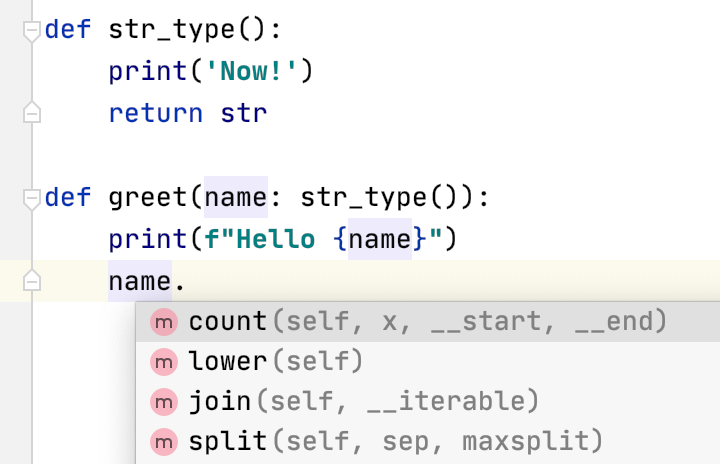
5Hello Martyprint("Now!") 求值Python 的类型提示还可以更复杂,而且 IDE 还能推算出它的实际的提示类型,看 PyCharm 中的提示
str_type() 函数返回的是 str 类型,所以 name. 能提示出 str 类型的方法。时间精度的提高
Python 3.7 对time 模块的某些函数上增加了 xxx_ns() 函数的支持,返回的是纳秒,并且类型为 int 而非原来的 float 类型,float 本质上不准确,而 Python 无限的 int 类型则更为优越。那些函数是clock_gettime_ns(): 返回指定时钟时间clock_settime_ns(): 设置指定时钟时间monotonic_ns(): 返回不能倒退的相对时钟的时间(例如由于夏令时)perf_counter_ns(): 返回性能计数器的值,专门用于测量短间隔的时钟process_time_ns(): 返回当前进程系统和用户 CPU 时间的总和(不包括休眠时间)time_ns(): 返回自 1970 年 1 月 1 日以来的纳秒数
字典的顺序是有保证的
Python 3.7 开始输出的字典顺序与放入 key 的顺序是一致的。Python 3.6 只是说字典的顺序基本可以保证,但不能过于依赖)。1>>> {"one": 1, "two": 2, "three": 3}
2{'one': 1, 'two': 2, 'three': 3}HashMap 实现为 LinkedHashMap。async 和 await 终于成了关键字
Python 3.5 开始引入了 async 和 await 语法,却未把它们当作关键字,也许是为了一个过度,所以在 Python 3.7 之前 async 和 await 可以用作变量或函数名。Python 3.7 开始就不被允许它们挪为它用了。asyncio.run() 简化事件循环
在 Python 3.7 之前支持协程要显示的使用事件循环,比如使用如下代码1# Python 3.7 之前
2import asyncio
3
4async def hello_world():
5 print("Hello World!")
6
7loop = asyncio.get_event_loop()
8loop.run_until_complete(hello_world())
9loop.close()asyncio.run() 方法,代码就变为1import asyncio
2
3async def hello_world():
4 print("Hello World!")
5
6asyncio.run(hello_world())asyncio.run() 就做了前方代码 loop 三行的事情。用 asyncio.run() 稍有不便之处就是总是需要定义一个入口执行函数。上下文变量(ContextVar)
它类似于线程本地存储, 和 Java 的下面几个概念对照起来就好理解了- ThreadLocal,set(value), get()
- 日志框架(如 SLF4J) 的 MDC.getCopyOfContextMap() 和 setContextMap
为了更好理解,需要放到多线程环境中去演示它,用下面的
ThreadPoolExecutor 代码 1from contextvars import ContextVar
2from concurrent.futures import ThreadPoolExecutor
3from threading import current_thread
4import time
5
6name = ContextVar("name", default='world')
7
8def task(num):
9 time.sleep(2)
10 if name.get() == 'world':
11 name.set(f'world #{num}')
12 print(f'{current_thread().name}: name = {name.get()}')
13
14with ThreadPoolExecutor(3) as executor:
15 for i in range(10):
16 executor.submit(task, i)name.get() 的值为默认的 world 才重设为 world <序号>, 执行后看到如下输出ThreadPoolExecutor-0_2: name = world #2发现只要重要线程时还能看到之前的值,也就是说
ThreadPoolExecutor-0_0: name = world #0
ThreadPoolExecutor-0_1: name = world #1
ThreadPoolExecutor-0_2: name = world #2
ThreadPoolExecutor-0_0: name = world #0
ThreadPoolExecutor-0_1: name = world #1
ThreadPoolExecutor-0_2: name = world #2
ThreadPoolExecutor-0_0: name = world #0
ThreadPoolExecutor-0_1: name = world #1
ThreadPoolExecutor-0_2: name = world #2
name 的值是绑定在当前线程上的。第二段代码,演示了如何应用指定的上下文变量去运行代码
1import contextvars
2from threading import current_thread
3from concurrent.futures import ThreadPoolExecutor
4
5name = contextvars.ContextVar("name", default='name1')
6address = contextvars.ContextVar("address", default='address1')
7
8def task(num):
9 print(num, current_thread().name, name.get(), address.get())
10
11name.set('name2')
12address.set('address2')
13ctx = contextvars.copy_context()
14
15with ThreadPoolExecutor(1) as executor:
16 executor.submit(task, 1)
17 executor.submit(lambda : ctx.run(task, 2))
18 executor.submit(task, 3)1 ThreadPoolExecutor-0_0 name1 address1使用一个单线程的线程池,使得每次任务都重用同一个线程,分别解释每一次的执行效果:
2 ThreadPoolExecutor-0_0 name2 address2
3 ThreadPoolExecutor-0_0 name1 address1
- 第一个任务使用本地默认的 name 和 address 值,分别为
name1和address1 - 第二个任务使用事先从主线程获得的
contextvars.copy_context()作为上下文去执行 task, 所以打印出的是主线程上的变量值name2和address1 - 第三个任务同样是打印出的默认值
name1和address1, 说明上一个任务不会覆盖当前线程的上下文变量值
小结
基本上对我比较有用的新特性就这些了,还有一个开发者技巧,用python3.7 -X importtime my_script.py 就能看到所有与 my_script.py 相关联的模块的导入时间,从而发现巨慢的模块加载予以优化。总体说来没多大的惊喜,毕竟是一个小版本的更新,想要惊喜的话得看 Python 3.0 的 What's New。如果这以上新特性较为有用的也就 数据类 和 上下文变量,但由于数据类不能被 JSON 序列化,在用作 Rest API 时还得转换为字典再序列化为 JSON。 永久链接 https://yanbin.blog/python-3-7-what-is-new/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。