Java StackOverflowError 与递归及尾递归优化
本篇同样是阅读《100 Java Mistakes and How to Avoid Them》的一则笔记,只是火力全集中在 StackOverflowError 这个单一主题之上, 且主要与递归及尾递归优化相关。一提到 StackOverflow, 恐怕首先是想到那个代码搬运源网站 stackoverflow.com,其次才是代码执行过程中的 StackOverflowError 错误。
什么是 StackOverflow, 准确来说是指线程的栈内存不足,无法在栈中分配新的内存(或创建新的栈帧)。我们通常会把它与方法调用关联起来,因为一次方法调用会创建一个新的栈帧,分配在栈上的局部变量(包括基本类型与对象引用),和栈帧都要占用线程栈内存。而我们平时所说的方法调用栈,或出现异常时打印出的异常栈都是一个概念。
StackOverflowError 一般出现在方法调用太深(方法调方法),手动编写的方法调用一般不容易达到这个限制,所以它与递归调用关系最为密切,递归调用次数太多或甚至没有出口条件无限递归; 也可能是经过一番递归调用后,再正常调用后续方法时出现 StackOverflowError(因为前面的递归调用资源消耗的差不多)
何谓递归调用,简单的说就是方法自己调用自己,从而实现循环的效果,或使代码更精练,例如经典排序中的快速和归并排序就要用到递归。但循环与递归又有本质上的区别,循环不增加调用深度;递归却不同,递归分递进与回归两个过程,递进调用时每次调用前都需通过压栈来保留现场,逆向回归时再逐级恢复现场,保留现场的过程就要从线程栈中分配内存空间; 死循环可能不会造成程序异常,但死(无限)递归必定出现 StackOverflowError。
我们知道 StackOverflowError 是由于线程栈内存不足造成的,方法调用层次太深会造成 StackOverflowError, 那么方法层次的最大深度是多少呢?答案是: 不确定。它受以下方面的影响
篇外:Python 中函数的调用深度是由 sys.getrecursionlimit() 限制的,默认为 1000,可由 sys.getrecursionlimit(10000) 配置最大的数字, 所以 Python 在调用深度超过 1000 就报错 "RecursionError: maximum recursion depth exceeded", 还无关乎栈内存溢出。
那我们就来探一下 Java 的方法调用最大深度,以下是测试代码 Test.java
这是一个无限递归调用,用来找到不同情况下出现 StackOverflowError 时方法 call 被调用的次数, 变该参数的个数和类型可影响到栈内存的分配。这里无法对 JIT 的影响进行模拟。
测试环境:macOS, 16G 内存,JDK 17,即使是相同的参数也测试多次
参数为 1,调用一个 int 参数的 call 方法,int 为 4 字节, 连续 5 次
那么前面提到的线程栈内存默认是多少,我们是否可以改变线程栈内存的大小呢?用下面的命令可显示出默认线程栈的大小
默认为 1M, 可用
标准的 JDK/JVM 实现不会对尾递归进行优化,可能某些虚拟机实现的 JIT 会这么做,但不保证,因此我们在 Java 在写递归调用时一定要考虑到可能发生的 StackOverflowError。在用 Scala 或 Kotlin 时,应尽可能用 @tailrec 注解或 tailrec 修饰明确要求编译器进行尾递归优化,凡是用了 @tailrec 和 tailrec 的地方若编译无误都会被成功转换成了循环,这样就避免了 StackOverflowError.
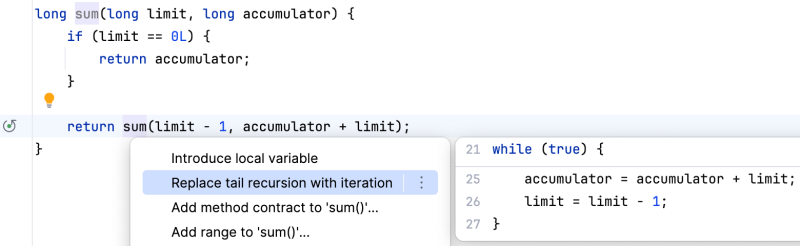
虽然 JDK/JVM 不对 Java 的尾递归进行优化,但某些 IDE 能对尾递归提供优化建议。下面以 IntelliJ IDEA 为例,用递归实现一个累加的函数,把光标移到最后一行的递归调用方法名上,然后按 Option + Enter (macOS), 就可选择
 应用该建议之后,代码会变成
应用该建议之后,代码会变成
我们姑且也可以把这叫做 Java IDE 对尾递归的优化,但必须手工处理。我们应该认真审视项目中所有的递归方法调用,处处思量是否会产生 StackOverflowError, 然后尽可能的把尾递归优化成循环语句。如果不是一个尾递归,但方法调用深度可能会超过限制,那么递归总是能想办法替换成循环操作的,或借助于 ArrayDeque 模拟类似的栈操作。
尾递归的优化的好处是显而易见的,比如我们这里的递归累加的例子,如果没有尾递归优化成循环,那么根据前面的测试结果,以默认
下面来看看 Scala 和 Kotlin 对尾递归优化后的效果
编译
用工具反编译 Test$package$.class 看到编译后的 sum() 方法实现为
尾递归自动转换成了循环
现在我们人为的把上面的 sum 方法干预为非递归调用,使之不能被尾递归优化,修改后的 sum 方法为
再用 scalac Test.scala 编译后,反编译 Test$package$.class 看到的 sum 方法保留为递归调用,而非循环
这时如果给 sum 方法强行冠上 @scala.annotaion.tailrec 注解就是勉为其难了,用 scalac Test.scala 编译或用 scala Test.scala 执行时都会报告如下错误
如果对修改前的 sum 方法前加上
编译
说明不同于 Scala, Kotlin 不会自动尝试进行尾递归优化。 给 sum 方法加上
再编译 kotlinc Test.kt, 字节码 TestKt.class 对应的 sum 方法就变成了
Kotlin 一定要给方法加上
把方法改成非尾递归调用,并保留
再用 kotlinc Test.kt 编译时就报错了
不能进行尾递归优化,只要拿掉
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
什么是 StackOverflow, 准确来说是指线程的栈内存不足,无法在栈中分配新的内存(或创建新的栈帧)。我们通常会把它与方法调用关联起来,因为一次方法调用会创建一个新的栈帧,分配在栈上的局部变量(包括基本类型与对象引用),和栈帧都要占用线程栈内存。而我们平时所说的方法调用栈,或出现异常时打印出的异常栈都是一个概念。
StackOverflowError 一般出现在方法调用太深(方法调方法),手动编写的方法调用一般不容易达到这个限制,所以它与递归调用关系最为密切,递归调用次数太多或甚至没有出口条件无限递归; 也可能是经过一番递归调用后,再正常调用后续方法时出现 StackOverflowError(因为前面的递归调用资源消耗的差不多)
何谓递归调用,简单的说就是方法自己调用自己,从而实现循环的效果,或使代码更精练,例如经典排序中的快速和归并排序就要用到递归。但循环与递归又有本质上的区别,循环不增加调用深度;递归却不同,递归分递进与回归两个过程,递进调用时每次调用前都需通过压栈来保留现场,逆向回归时再逐级恢复现场,保留现场的过程就要从线程栈中分配内存空间; 死循环可能不会造成程序异常,但死(无限)递归必定出现 StackOverflowError。
我们知道 StackOverflowError 是由于线程栈内存不足造成的,方法调用层次太深会造成 StackOverflowError, 那么方法层次的最大深度是多少呢?答案是: 不确定。它受以下方面的影响
- 栈中分配的局部变量 -- 基本类型或对象引用(包括方法参数与返回值)
- JIT 优化
- 给 JVM 分配的线程栈空间大小
篇外:Python 中函数的调用深度是由 sys.getrecursionlimit() 限制的,默认为 1000,可由 sys.getrecursionlimit(10000) 配置最大的数字, 所以 Python 在调用深度超过 1000 就报错 "RecursionError: maximum recursion depth exceeded", 还无关乎栈内存溢出。
那我们就来探一下 Java 的方法调用最大深度,以下是测试代码 Test.java
1public class Test {
2 private static int count = 0;
3
4 public static void main(String[] args) {
5 try {
6 switch (args[0]){
7 case "1":
8 call(2);
9 case "2":
10 call(2, 2, 2, 2, 2);
11 case "3":
12 call(2L, 2L, 2L, 2L, 2L);
13 }
14 } catch (StackOverflowError error) {
15 System.out.println(count);
16 }
17 }
18
19 static void call(int a) {
20 count++;
21 call(a);
22 }
23
24 static void call(int a, int b, int c, int d, int e) {
25 count++;
26 call(a, b, c, d, e);
27 }
28
29 static void call(long a, long b, long c, long d, long e) {
30 count++;
31 call(a, b, c, d, e);
32 }
33}这是一个无限递归调用,用来找到不同情况下出现 StackOverflowError 时方法 call 被调用的次数, 变该参数的个数和类型可影响到栈内存的分配。这里无法对 JIT 的影响进行模拟。
测试环境:macOS, 16G 内存,JDK 17,即使是相同的参数也测试多次
参数为 1,调用一个 int 参数的 call 方法,int 为 4 字节, 连续 5 次
$ for i in {1..5}; do; java Test 1; done参数为 2,调用有五个 int 参数的 call 方法,连续 5 次
21863
21698
22070
21957
21951
$ for i in {1..5}; do; java Test 2; done参数为 3,调用有五个 long 参数的 call 方法, long 为 8 字节,连续 5 次
13552
13686
13526
13558
13110
$ for i in {1..5}; do; java Test 3; done前面测试看到通过局部变量可以挤压掉方法的调用深度。我们看到即使是相同的执行条件,每次最大的方法调用深度也有区别,这更回答了不确定性。那什么是确定的呢,测试条件相似,改变线程栈内存大小可调整大概的调用深度。
8288
8440
8469
8544
8440
那么前面提到的线程栈内存默认是多少,我们是否可以改变线程栈内存的大小呢?用下面的命令可显示出默认线程栈的大小
1$ java -XX:+PrintFlagsFinal --version | grep StackSize
2 intx CompilerThreadStackSize = 1024 {pd product} {default}
3 size_t MarkStackSize = 4194304 {product} {ergonomic}
4 size_t MarkStackSizeMax = 536870912 {product} {default}
5 intx ThreadStackSize = 1024 {pd product} {default}
6 intx VMThreadStackSize = 1024 {pd product} {default}默认为 1M, 可用
-Xss JVM 参数修改它的值。如果修改为 2M 重新跑上面的测试,来看看结果$ for i in {1..5}; do; java -Xss2m Test 1; done果然立竿见影,所以我们可以根据实际需求修改线程栈的大小。比如有一个带有许多参数,或很多局部变量的递归调用,因为默认线程栈内存太小,可能递归调用几百次就抛出了 StackOverflowError, 那么适当的用
48165
48104
48046
48255
78302 $ for i in {1..5}; do; java -Xss2m Test 2; done
29462
29806
30007
29590
29897 $ for i in {1..5}; do; java -Xss2m Test 3; done
18442
35296
31661
18579
18424
-Xss 调整线程栈内存还是有必要的。尾递归优化
有些语言,特别是函数式编程语言,能够对尾递归(递归调用出现在函数的最后一条语句)进行优化,即把递归转换为循环,这样就消除了 StackOverflowError 的产生。Scala 语言会自动进行尾递归优化,加上 @tailrec 注解时如果不能进行尾递归优化则在编译期出错,比如非尾递归调用。在 Kotlin 中需加上 tailrec 修饰指示尾递归优化,否则不进行优化。标准的 JDK/JVM 实现不会对尾递归进行优化,可能某些虚拟机实现的 JIT 会这么做,但不保证,因此我们在 Java 在写递归调用时一定要考虑到可能发生的 StackOverflowError。在用 Scala 或 Kotlin 时,应尽可能用 @tailrec 注解或 tailrec 修饰明确要求编译器进行尾递归优化,凡是用了 @tailrec 和 tailrec 的地方若编译无误都会被成功转换成了循环,这样就避免了 StackOverflowError.
虽然 JDK/JVM 不对 Java 的尾递归进行优化,但某些 IDE 能对尾递归提供优化建议。下面以 IntelliJ IDEA 为例,用递归实现一个累加的函数,把光标移到最后一行的递归调用方法名上,然后按 Option + Enter (macOS), 就可选择
Replace tail recursion with iteration, 递归调用也会在左列标示出来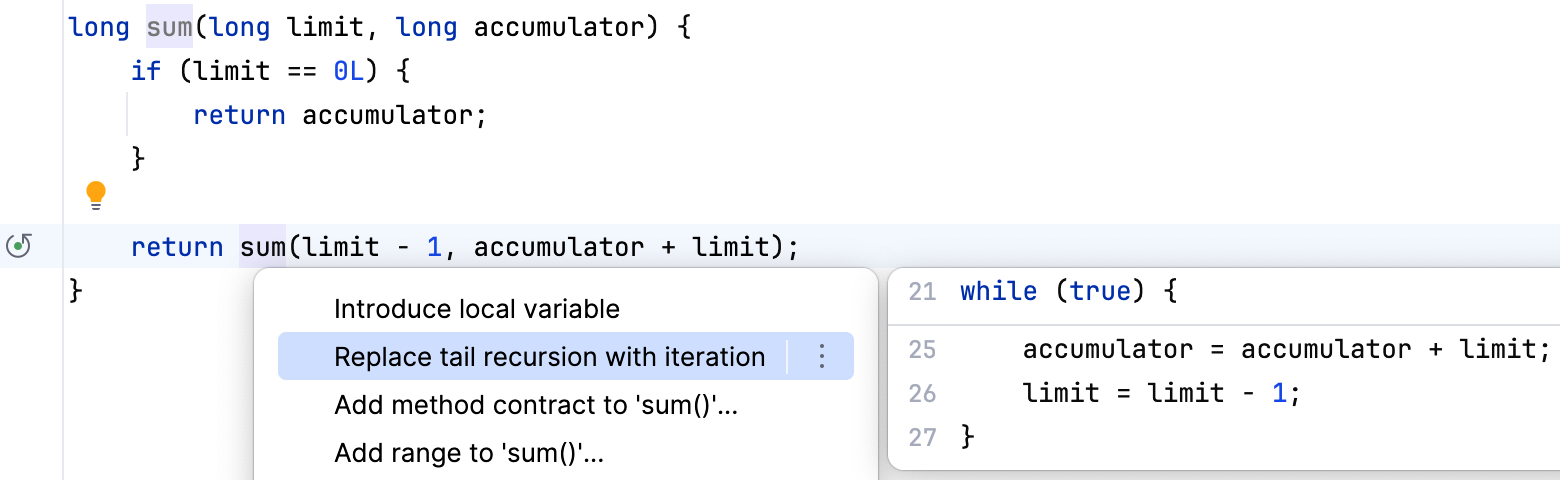 应用该建议之后,代码会变成
应用该建议之后,代码会变成 1long sum(long limit, long accumulator) {
2 while (true) {
3 if (limit == 0L) {
4 return accumulator;
5 }
6
7 accumulator = accumulator + limit;
8 limit = limit - 1;
9 }
10}我们姑且也可以把这叫做 Java IDE 对尾递归的优化,但必须手工处理。我们应该认真审视项目中所有的递归方法调用,处处思量是否会产生 StackOverflowError, 然后尽可能的把尾递归优化成循环语句。如果不是一个尾递归,但方法调用深度可能会超过限制,那么递归总是能想办法替换成循环操作的,或借助于 ArrayDeque 模拟类似的栈操作。
尾递归的优化的好处是显而易见的,比如我们这里的递归累加的例子,如果没有尾递归优化成循环,那么根据前面的测试结果,以默认
-Xss1M 的线程栈内存都无法完成 1 到 30000 的累加操作,必定会出现 StackOverflowError, 而转换成循环再大的数字都能累加,只是数值太大了会安安静静的溢出而呈现错误的结果。下面来看看 Scala 和 Kotlin 对尾递归优化后的效果
Scala 尾递归优化
Test.scala 1def sum(limit: Long, accumulator: Long = 0): Long = {
2 if (limit == 0L) {
3 return accumulator
4 }
5 sum(limit - 1, accumulator + limit)
6}
7
8
9def main(args: Array[String]): Unit = {
10 println(sum(100))
11}编译
scalac Test.scala编译产生文件 Test$package$.class Test$package.class Test$package.tasty. 直接用
scala Test.scala 不会在当前目录下产生相应的 class/tasty 文件用工具反编译 Test$package$.class 看到编译后的 sum() 方法实现为
1 public long sum(long limit, long accumulator) {
2 long l1 = accumulator, l2 = limit;
3 while (true) {
4 if (l2 == 0L)
5 return l1;
6 long l3 = l2 - 1L, l4 = l1 + l2;
7 l2 = l3;
8 l1 = l4;
9 }
10 }尾递归自动转换成了循环
现在我们人为的把上面的 sum 方法干预为非递归调用,使之不能被尾递归优化,修改后的 sum 方法为
1def sum(limit: Long, accumulator: Long = 0): Long = {
2 if (limit == 0L) {
3 return accumulator
4 }
5 var t = sum(limit - 1, accumulator + limit)
6 return t
7}再用 scalac Test.scala 编译后,反编译 Test$package$.class 看到的 sum 方法保留为递归调用,而非循环
1 public long sum(long limit, long accumulator) {
2 if (limit == 0L)
3 return accumulator;
4 long t = sum(limit - 1L, accumulator + limit);
5 return t;
6 }这时如果给 sum 方法强行冠上 @scala.annotaion.tailrec 注解就是勉为其难了,用 scalac Test.scala 编译或用 scala Test.scala 执行时都会报告如下错误
16 | var t = sum(limit - 1, accumulator + limit)
2 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
3 | Cannot rewrite recursive call: it is not in tail position如果对修改前的 sum 方法前加上
@tailrec 是没问题的。用 @tailrec 确定产生的字节码是否被优化为循环,建议总是使用。Kotlin 尾递归优化
类似的 Kotlin 代码 Test.kt 1fun sum(limit: Long, accumulator: Long = 0): Long {
2 if (limit == 0L) {
3 return accumulator
4 }
5 return sum(limit - 1, accumulator + limit)
6}
7
8fun main() {
9 println(sum(100))
10}编译
kotlinc Test.kt得到 TestKt.class 以及 META-INF 目录,反编译 TestKt.class 文件,看到 sum 方法的实现
1 public static final long sum(long limit, long accumulator) {
2 if (limit == 0L)
3 return accumulator;
4 return sum(limit - 1L, accumulator + limit);
5 }说明不同于 Scala, Kotlin 不会自动尝试进行尾递归优化。 给 sum 方法加上
tailrec 修饰,sum 方法变为1tailrec fun sum(limit: Long, accumulator: Long = 0): Long {
2 if (limit == 0L) {
3 return accumulator
4 }
5 return sum(limit - 1, accumulator + limit)
6}再编译 kotlinc Test.kt, 字节码 TestKt.class 对应的 sum 方法就变成了
1 public static final long sum(long limit, long accumulator) {
2 while (true) {
3 if (limit == 0L)
4 return accumulator;
5 long l1 = limit - 1L, l2 = accumulator + limit;
6 limit = l1;
7 accumulator = l2;
8 }
9 }Kotlin 一定要给方法加上
tailrec 修饰才会进行了尾递归优化把方法改成非尾递归调用,并保留
tailrec 修饰1tailrec fun sum(limit: Long, accumulator: Long = 0): Long {
2 if (limit == 0L) {
3 return accumulator
4 }
5 var t = sum(limit - 1, accumulator + limit)
6 return t
7}再用 kotlinc Test.kt 编译时就报错了
1kotlinc Test.kt
2Test.kt:1:1: warning: a function is marked as tail-recursive but no tail calls are found
3tailrec fun sum(limit: Long, accumulator: Long = 0): Long {
4^
5Test.kt:5:13: warning: recursive call is not a tail call
6 var t = sum(limit - 1, accumulator + limit)
7 ^不能进行尾递归优化,只要拿掉
tailrec 修饰就行了防备无限递归
最后,要注意防备无限递归调用,可能下面一些情况会产生无限递归- 在方法中错误的调用了自己(原本要调用 Delegate 的同名方法)
- 遍历有循环引用的数据结构,比如遍历带有符号引用或递归挂载文件系统的目录结构
- 当集合中包含自己时,某些方法会产生无限递归调用,如下
1List<Object> list = new ArrayList<>(); 2list.add(list); // IntelliJ IDEA 中会有警告:'add()' called on collection 'list' with itself as argument 3list.hashCode(); // 会产生 StackOverflowError 4list.toString(); // 这行没问题 5 6list.set(0, List.of(list)); 7list.toString(); // 但这会出现 StackOverflowError
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。