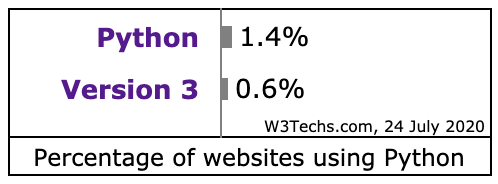
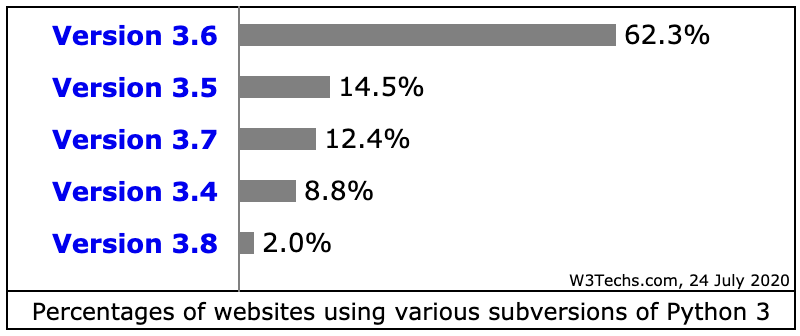
自去年 10 月底搬家后就基本没再写日志了,其间常登陆后台看到 WordPress 及其插件不停的有提示升级,每次都是能升就就升,至少前台的页面显示没多大问题。只有过一个小问题,左边最新评论的 Widget 显示不出东西来,把最后更新日期为 8 年前的 WP-RecentComments 插件变成了 Decent Comments 后解决。
昨天才开始琢磨着写一篇关于 Mockito Mock 静态方法的日志,才意识到一直以来不知拒绝的跟风似的升级 WordPress 主体和插件给后台带来了不得不面对的问题。
首先,传文件总是失败,在 Media 或 Add Media 时也无法浏览图片,翻看 Apache2 的错误日志也没找到问题。无奈,手工通过 SCP 上传吧,一登陆到服务器上却发现即使界面提示失败,但文件实际上是在已上传到了服务器上了的。先这么着吧,切换编辑器到文本模式手工写 <img> 标签来引用图片。 阅读全文 >>