AWS DynamoDB 的常用操作
AWS 提供的 NoSQL 数据库有 DynamoDB, DocumentDB(即 MongoDB), 和 Keyspaces(即 Cassandra)。还有一个神秘的早已消失于 AWS 控制台之外的 SimpleDB,它只能通过 API 才能使用。因为 AWS 有意要把它藏起来,不愿被新用户看到它,希望用 DynamoDB 替代它,关于用 aws cli 如何体验 AWS SimpleDB 可见本文后面部分。
DynamoDB 所设计的读写容量参数的概念,AWS 为其标榜是为保证一致性与明确的性能表现,实际上不如说是一个赚钱的计量单位,为了钱反而是把一个简单的事情弄复杂了。当需要全局索引时,必须为全局索引设定读写容量,连索引的钱也不放过。本文只为体验对 DynamoDB 的常用操作,不管吞吐量的问题,所以不用关心读写容量的问题。
DynamoDB 后端用 SSD 存储,不像 Elasticache 是把数据放在内存当,对了 Elasticache 也是 AWS 提供了 NoSQL 服务。DynamoDB 每条记录(Item) 的大小限制为 400K.
我们在使用 DynamoDB 的 Python API 时,get_item, query, scan 等的操作不能像常规数据库那样去思维,get_item, query 等主要操作方法都必须作用在主键上(如果是组合主键,需全列出),或是额外的索引上。scan 可以用主键或索引外的条件,但它会进行全表扫描,对于大量记录的表慎用。
如果去参考官方 boto3 的 DynamoDB API,https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/dynamodb.html,那是非常不具参考性的,也就是无法照着文档来操作,还必须用 Google 找例子。
用 Python 的 boto3 API 操作 DynamoDB 的表时有低阶和高阶的 API
用 client 进行表的操作时须指定表名,并且参数中必说明每个字段的类型。
因为该表的主键为 id, 再次 put_item 一条 id 为 2 的记录 DynamoDB 并不会报错,操作是成功的,变成了对 id 为 2 记录的更新操作,相当于是
后面直接用高阶的 table 来操作
用 Key 参数,只能指定主键值进行查询,如果试图在 Key 中指定别的字段值,如
将会看到错误信息
既然是叫做
scan() 就比较随意, 可用任意字段作为查询条件,反正是要全表扫描。scan() 也能根据索引来扫描,可以缩小扫描的范围。
错误为
创建一个表,只有 Partiton Key 为 id, 并创建以 name 它段的全局二级索引 nameIndex
创建完后可以看到这么一个索引
就能通过 http://localhost 访问,像用
Python 的操作的话,在创建 DynamoDB client 或 resource 时需加上 endpoint_url 参数,如下
其他的操作就没什么分别了。
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
DynamoDB 所设计的读写容量参数的概念,AWS 为其标榜是为保证一致性与明确的性能表现,实际上不如说是一个赚钱的计量单位,为了钱反而是把一个简单的事情弄复杂了。当需要全局索引时,必须为全局索引设定读写容量,连索引的钱也不放过。本文只为体验对 DynamoDB 的常用操作,不管吞吐量的问题,所以不用关心读写容量的问题。
DynamoDB 后端用 SSD 存储,不像 Elasticache 是把数据放在内存当,对了 Elasticache 也是 AWS 提供了 NoSQL 服务。DynamoDB 每条记录(Item) 的大小限制为 400K.
我们在使用 DynamoDB 的 Python API 时,get_item, query, scan 等的操作不能像常规数据库那样去思维,get_item, query 等主要操作方法都必须作用在主键上(如果是组合主键,需全列出),或是额外的索引上。scan 可以用主键或索引外的条件,但它会进行全表扫描,对于大量记录的表慎用。
如果去参考官方 boto3 的 DynamoDB API,https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/dynamodb.html,那是非常不具参考性的,也就是无法照着文档来操作,还必须用 Google 找例子。
单主键表(Partition Key Only)
创建一个单主键的表(即只有 partition key 无 sort key)$ aws dynamodb create-table --table-name test-table \这样创建的表只有一个 partition key, 没有 sort key, 那么该表的主键就是 partition key,字段 id
--attribute-definitions AttributeName=id,AttributeType=N \
--key-schema AttributeName=id,KeyType=HASH \
--billing-mode PROVISIONED \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5
用 Python 的 boto3 API 操作 DynamoDB 的表时有低阶和高阶的 API
1import boto3
2client = boto3.client('dynamodb')
3table = boto3.client('dynamodb').Table('test-table')用 client 进行表的操作时须指定表名,并且参数中必说明每个字段的类型。
put_item()
1client.put_item(
2 TableName='test-table',
3 Item = {'id': {'N': '1'}, 'name': {'S': 'scott'}, 'city': {'S': 'Chicago'}}
4)
5
6table.put_item(
7 Item = {'id': 2, 'name': 'tiger', 'city': 'LA'}
8)因为该表的主键为 id, 再次 put_item 一条 id 为 2 的记录 DynamoDB 并不会报错,操作是成功的,变成了对 id 为 2 记录的更新操作,相当于是
put_item() 有幂等性。如果需要更新所有字段值都不需要用 update_item() 函数,直接用 put_item() 就行。后面直接用高阶的 table 来操作
get_item()
1res = table.get_item(
2 Key = {'id': 1}
3)
4res['Item'] # {'city': 'Chicagi', 'id': Decimal('1'), 'name': 'scott'}用 Key 参数,只能指定主键值进行查询,如果试图在 Key 中指定别的字段值,如
1table.get_item(Key={'name': 'scott'}) # 这是不对的将会看到错误信息
ClientError: An error occurred (ValidationException) when calling the GetItem operation: The provided key element does not match the schema
query()
1from boto3.dynamodb.conditions import Key
2
3res = table.query(
4 KeyConditionExpression=Key('id').eq(1)
5)
6res['Items'] # [{'city': 'Chicagi', 'id': Decimal('1'), 'name': 'scott'}]既然是叫做
KeyConditionXxx, 也只能用主键。我们后面会看到有索引的情况可用 query() 函数根据索引来查询scan()
1from boto3.dynamodb.conditions import Attr
2
3res = table.scan(
4 FilterExpression=Attr('name').contains('t')
5)
6res['Items'] # [{'city': 'LA', 'id': Decimal('2'), 'name': 'tiger'},
7 {'city': 'Chicagi', 'id': Decimal('1'), 'name': 'scott'}]scan() 就比较随意, 可用任意字段作为查询条件,反正是要全表扫描。scan() 也能根据索引来扫描,可以缩小扫描的范围。
有 Partition Key 和 Sort Key 的表
再来创建一个含 Partition Key 和 Sort Key 的表aws dynamodb create-table --table-name test-table \这时候该表的主键就是 id(partition key) 和 name(sort key) 的组合,可以有 id 相同但 name 不同的记录,反之亦然。所以在
--attribute-definitions AttributeName=id,AttributeType=N \
AttributeName=name,AttributeType=S \
--key-schema AttributeName=id,KeyType=HASH \
AttributeName=name,KeyType=RANGE \
--billing-mode PROVISIONED \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5
put_item() 时当 id 与 name 有存在的记录时,变成了更新原记录。scan() 针对这种双 Key 的表也没什么特别的,反正是全扫描,无所谓主键是什么。get_item()
注意get_item() 和 query() 时必须同时列出 partition key 和 sort key, 否则会报错,比如下面试图只用 partition key 进行 get_item() 时1res = table.get_item( Key = {'id': 1} ) # 这是不对的错误为
ClientError: An error occurred (ValidationException) when calling the GetItem operation: The provided key element does not match the schema所以正确的
get_item() 代码是1res = table.get_item(
2 Key = {'id': 2, 'name': 'tiger'}
3)
4res['Item'] # {'city': 'LA', 'id': Decimal('2'), 'name': 'tiger'}query()
query() 和 get_item() 也是一样的,必须列出两个 key, 否则报一样的错误1from boto3.dynamodb.conditions import Key
2
3res = table.query(
4 KeyConditionExpression=Key('id').eq(1) & Key('name').begins_with('s')
5)
6res['Items'] # [{'city': 'Chicagi', 'id': Decimal('1'), 'name': 'scott'}]带全局索引的表
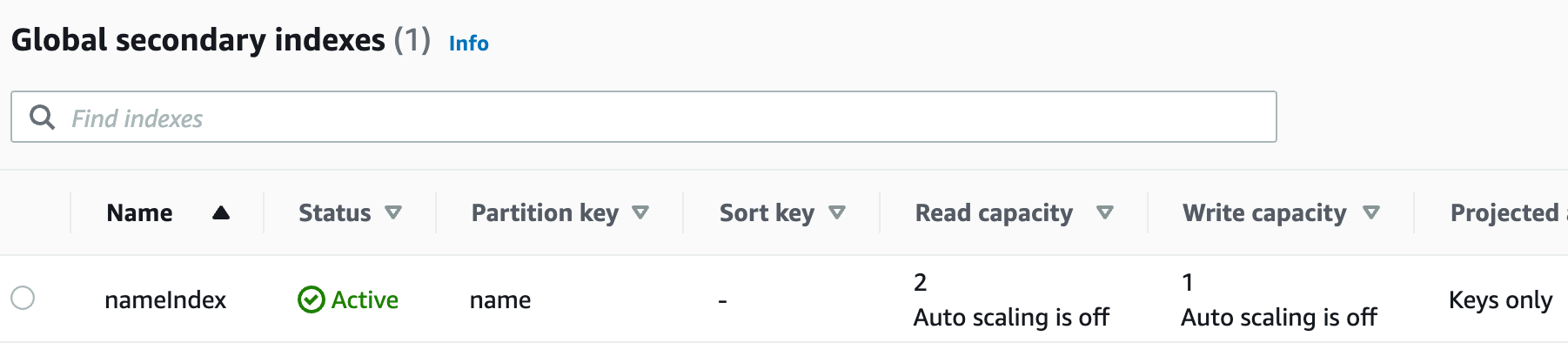
query() 操作必须同时列出所有的 Key, 如果在不知道 Key 的值,想用 query() 查询除 Key 之外的字段,却又想避免全表扫描的话,该如何做呢?全局二级索引:为非 Key 字段建立全局二级索引。DynamoDB 每建立一个全局索引时还必须为该索引单独设定读写容量。创建一个表,只有 Partiton Key 为 id, 并创建以 name 它段的全局二级索引 nameIndex
1aws dynamodb create-table --table-name test-table \ 2--attribute-definitions AttributeName=id,AttributeType=N \ 3 AttributeName=name,AttributeType=S \ 4--key-schema AttributeName=id,KeyType=HASH \ 5--billing-mode PROVISIONED \ 6--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 \ 7--global-secondary-indexes \ 8 '[ 9 { 10 "IndexName": "nameIndex", 11 "KeySchema": [ 12 {"AttributeName": "name", "KeyType":"HASH"} 13 ], 14 "Projection": { 15 "ProjectionType": "KEYS_ONLY" 16 }, 17 "ProvisionedThroughput": { 18 "ReadCapacityUnits": 2, 19 "WriteCapacityUnits": 1 20 } 21 } 22 ]'
创建完后可以看到这么一个索引
根据索引 query
有了全局二级索引后,在query() 时就不用列出所有的 Key, 而只根据索引来查询1from boto3.dynamodb.conditions import Key
2
3res = table.query(IndexName='nameIndex', KeyConditionExpression=Key('name').eq('tiger'))
4res['Items'] # [{'id': Decimal('2'), 'name': 'tiger'}]小小感受
总之呢?相比于关系型数据库,DynamoDB 把各种操作弄得很复杂,而流行已久的 MongoDB 可比 DynamoDB 编程上更友好。体验了上面的一番后,DynamoDB 用 Partition 来提高性能,但用读写容量来卡脖子,就看你敢不敢用; 考虑到多处读写容量的设置,不多给钱,读写容量不足很影响性能,这样还不如使用 ElastiCache 中的 Redis 内存缓存。本地版 DynamoDB
DynamoDB 还有一个为本地开发测试用的版本,见 Deploy DynamoDB Locally on Your Computer. 其中拣一个地址下载,如 https://s3.ap-south-1.amazonaws.com/dynamodb-local-mumbai/dynamodb_local_latest.tar.gz, 下载后解压缩,运行$ java -jar DynamoDBLocal.jar -sharedDb或用
-inMemory 参数,数据只写在内存当中,-port 可改变端口号,-help 查看更多使用参数。就能通过 http://localhost 访问,像用
aws dynamodb 命令时加上 --endpoint-url http://localhost:8000 就指向了本地版的 DynamoDB, 如用 aws dynamodb 创建一个表aws dynamodb create-table --table-name test-table \在使用本地的 DynamoDB 创建表时也必须指定读写容量,不过可以放大数字,反正不会有人收你的钱。
--attribute-definitions AttributeName=id,AttributeType=N \
--key-schema AttributeName=id,KeyType=HASH \
--billing-mode PROVISIONED \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 \
--endpoint-url http://localhost:8000
Python 的操作的话,在创建 DynamoDB client 或 resource 时需加上 endpoint_url 参数,如下
1client = boto3.client('dynamodb', endpoint_url='http://localhost:8000')
2table = boto3.resource('dynamodb', endpoint_url='http://localhost:8000').Table('test-table') 其他的操作就没什么分别了。
aws cli 体验 SimpleDB
这里给 AWS SimpleDB 兜个底,因为看到多方介绍 AWS 有个 SimpleDB, 但总也在 AWS 控制台找不着,所以用 aws cli 来体验一下$ aws sdb create-domain --domain-name test-domain链接:
$ aws sdb list-domains
{
"DomainNames": [
"test-domain"
]
}
$ aws sdb put-attributes --domain-name test-domain --item-name r1 --
attributes '{"Name": "yanbin", "Value": 0, "Replace": false}'
$ aws sdb get-attributes --domain-name test-domain --item-name r1
{
"Attributes": [
{
"Name": "yanbin",
"Value": "0"
}
]
}
$ aws sdb delete-domain --domain-name test-domain
- The Three DynamoDB Limits You Need to Know
- Ten Examples of Getting Data from DynamoDB with Python and Boto3
- Hands-On Examples for Working with DynamoDB, Boto3, and Python
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。