AWS Lambda 中使用 Python 并发编程
无论在何处,有多重任务要处理时,并发编程总是要得到考虑的。比如有 IO 等待时的并发或 CPU 密集型时的并行计算,并发通常是指在同一个 CPU 上按时间片轮换执行,并行是任务在不同的 CPU 上执行。能有效使用 CPU 多核的语言可以让线程运行在不同的核上实现并行,如果是启动的子进程能由操作系统运行在其他 CPU 核上。
回到 AWS Lambda 中的 Python 代码,如果是处理 IO 等待,使用多线程并发就行,大致的代码如下:
如果是 CPU 密集型的任务,用 Python 的多线程就要歇菜了,因为存在著名的 Python's GIL 的约束。 这时候就必须要考虑多进程并行的方式,同时应知晓当前选择的 Lambda 运行环境有多少个 CPU 内核,因为如果是单核的话再多进程也无济于事,没必要启动多于核心数的进程。 底下是本人上篇博客测试收集的不同 AWS Lambda 内存选择对应的 CPU 核心数,以及实际可用内存大小的关系表
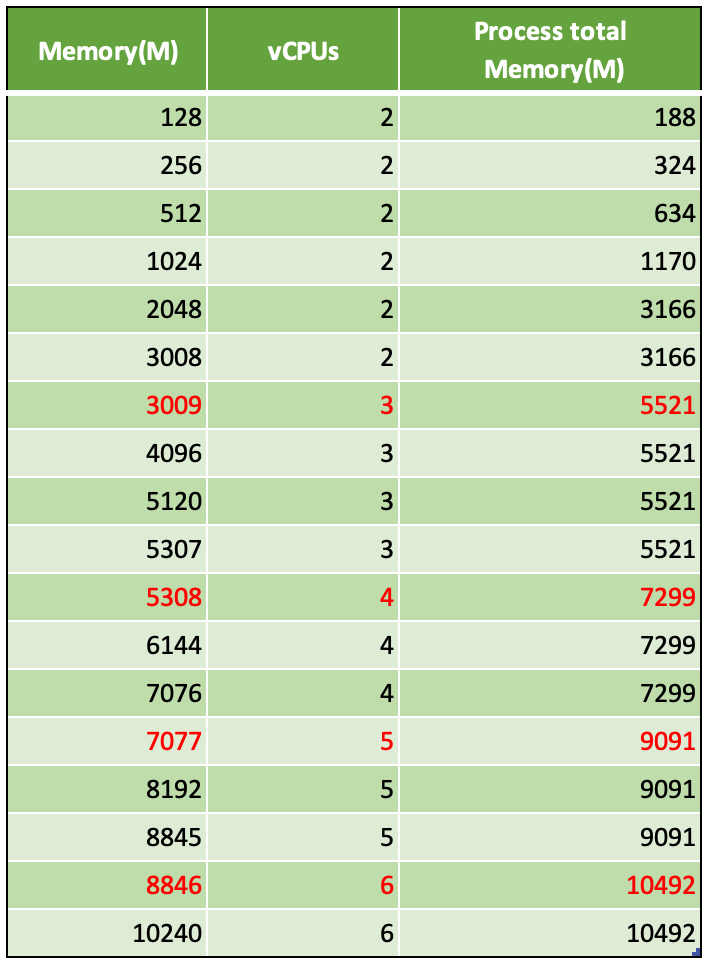
这个表格可帮助我们规划应启动的进程数量,CPU 核心数应以实际运行环境为准。
于是我们试着在 AWS Lambda 中使用进程池
测试 Lambda,很不幸,无法执行,得到的错误是
Function not implemented,以上多进程代码在本地放在 if __name__ == '__main__': 当中是没问题的。
再试下
类似的错误信息
问题大概都出在任务队列上,通过 Google 找到 Parallel Processing in Python with AWS Lambda, 原因是
直接部署 Python 代码到 AWS Lambda 的方式无法使用进程池,那么用 Docker image 的方式部署来试下。简单创建一个 Dockerfile
并有 lambda_function.py 文件,在其中使用了
发布后测试 Lambda 仍然是一样的问题,看来 AWS Lambda 才不在乎在 Docker 镜像中有没有 /dev/shm 目录,继续较真,在 lambda_function.py 中加上代码
测试该用 Docker 镜像部署的 Python Lambda,列出在 "/dev" 目录下的文件只有
继续大胆的去试,既然 Python 内置的 multiprocessing 不行,那么试下 multiprocess 如何,安装用
试过了 loky 组件也没用,看来只能退回到使用最原始的 Process 来创建子进程了, 通过进程间的管道(Pipe)来传递结果数据,最终在 AWS Lambda 要使用 Python 进程的话,只能是
测试 Lambda,得到响应
这是目前经过一番探索之后所知道的唯一可用在 AWS Lambda 中启动 Python 子进程的方法。
May, 12, 2023 注:除了 join() 之外还能用 wait 方法来等待进程的结束。wait 作用到 connection 列表的话,只要其中有 connection 是 ready 的话就会返回,所以以反复检查。
链接:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
回到 AWS Lambda 中的 Python 代码,如果是处理 IO 等待,使用多线程并发就行,大致的代码如下:
with ThreadPoolExecutor(10) as executor:以上代码在 AWS Lambda 中是可以运行的。
result = executor.map(task_function, task_inputs)
如果是 CPU 密集型的任务,用 Python 的多线程就要歇菜了,因为存在著名的 Python's GIL 的约束。 这时候就必须要考虑多进程并行的方式,同时应知晓当前选择的 Lambda 运行环境有多少个 CPU 内核,因为如果是单核的话再多进程也无济于事,没必要启动多于核心数的进程。 底下是本人上篇博客测试收集的不同 AWS Lambda 内存选择对应的 CPU 核心数,以及实际可用内存大小的关系表
这个表格可帮助我们规划应启动的进程数量,CPU 核心数应以实际运行环境为准。
于是我们试着在 AWS Lambda 中使用进程池
1import os
2from concurrent.futures import ProcessPoolExecutor
3
4def f(x):
5 return f'{os.getpid()}: {x*x}'
6
7def lambda_handler(event, context):
8 with ProcessPoolExecutor(max_workers=5) as executor:
9 results = executor.map(f, [1, 3, 4])
10 for i in results:
11 print(i) 1{
2 "errorMessage": "[Errno 38] Function not implemented",
3 "errorType": "OSError",
4 "requestId": "c933cb97-da3b-4e3f-bdc1-75c310d431e8",
5 "stackTrace": [
6 " File \"/var/task/lambda_function.py\", line 9, in lambda_handler\n with ProcessPoolExecutor(max_workers=5) as executor:\n",
7 " File \"/var/lang/lib/python3.9/concurrent/futures/process.py\", line 649, in __init__\n self._call_queue = _SafeQueue(\n",
8 " File \"/var/lang/lib/python3.9/concurrent/futures/process.py\", line 168, in __init__\n super().__init__(max_size, ctx=ctx)\n",
9 " File \"/var/lang/lib/python3.9/multiprocessing/queues.py\", line 43, in __init__\n self._rlock = ctx.Lock()\n",
10 " File \"/var/lang/lib/python3.9/multiprocessing/context.py\", line 68, in Lock\n return Lock(ctx=self.get_context())\n",
11 " File \"/var/lang/lib/python3.9/multiprocessing/synchronize.py\", line 162, in __init__\n SemLock.__init__(self, SEMAPHORE, 1, 1, ctx=ctx)\n",
12 " File \"/var/lang/lib/python3.9/multiprocessing/synchronize.py\", line 57, in __init__\n sl = self._semlock = _multiprocessing.SemLock(\n"
13 ]
14}再试下
multiprocessing.Pool, 代码1import os
2from multiprocessing import Pool
3
4def f(x):
5 return f'{os.getpid()}: {x*x}'
6
7def lambda_handler(event, context):
8 with Pool(5) as p:
9 print(p.map(f, [1, 2, 3])) 类似的错误信息
1{
2 "errorMessage": "[Errno 38] Function not implemented",
3 "errorType": "OSError",
4 "requestId": "63b9da65-e2e7-4e47-b561-260583e9234f",
5 "stackTrace": [
6 " File \"/var/task/lambda_function.py\", line 9, in lambda_handler\n with Pool(5) as p:\n",
7 " File \"/var/lang/lib/python3.9/multiprocessing/context.py\", line 119, in Pool\n return Pool(processes, initializer, initargs, maxtasksperchild,\n",
8 " File \"/var/lang/lib/python3.9/multiprocessing/pool.py\", line 191, in __init__\n self._setup_queues()\n",
9 " File \"/var/lang/lib/python3.9/multiprocessing/pool.py\", line 343, in _setup_queues\n self._inqueue = self._ctx.SimpleQueue()\n",
10 " File \"/var/lang/lib/python3.9/multiprocessing/context.py\", line 113, in SimpleQueue\n return SimpleQueue(ctx=self.get_context())\n",
11 " File \"/var/lang/lib/python3.9/multiprocessing/queues.py\", line 341, in __init__\n self._rlock = ctx.Lock()\n",
12 " File \"/var/lang/lib/python3.9/multiprocessing/context.py\", line 68, in Lock\n return Lock(ctx=self.get_context())\n",
13 " File \"/var/lang/lib/python3.9/multiprocessing/synchronize.py\", line 162, in __init__\n SemLock.__init__(self, SEMAPHORE, 1, 1, ctx=ctx)\n",
14 " File \"/var/lang/lib/python3.9/multiprocessing/synchronize.py\", line 57, in __init__\n sl = self._semlock = _multiprocessing.SemLock(\n"
15 ]
16}问题大概都出在任务队列上,通过 Google 找到 Parallel Processing in Python with AWS Lambda, 原因是
Due to the Lambda execution environment not having /dev/shm (shared- memory for processes) support, you can’t use multiprocessing.Queue or multiprocessing.Pool.没有 /dev/shm 文件作为进程间共享内存,所以无法使用进程池的 Queue。在 Linux 下存在 /dev/shm, 而 Mac 下不使用 /dev/shm 文件,因此也不存在。
直接部署 Python 代码到 AWS Lambda 的方式无法使用进程池,那么用 Docker image 的方式部署来试下。简单创建一个 Dockerfile
1FROM public.ecr.aws/lambda/python:3.9<br/>
2COPY lambda_function.py ./
3CMD [ "lambda_function.lambda_handler" ]并有 lambda_function.py 文件,在其中使用了
ProcessPoolExecutor,部署后测试,同样的问题{看来 Docker Image 部署 Lambda 的方式也不管用,不过用 docker run 运行该 Docker 镜像,在容器中确是存在 /dev/shm 文件
"errorMessage": "[Errno 38] Function not implemented",
"errorType": "OSError",
"requestId": "0cbd90fe-1832-459c-8d79-1e7b28b561fa",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 9, in lambda_handler\n with ProcessPoolExecutor(max_workers=5) as executor:\n",
.................
$ docker run -it --entrypoint sh 123456789000.dkr.ecr.us-east-1.amazonaws.com/test-lambda:latest所以即使不使用 AWS 官方的基础镜像 public.cr.aws/lambda/python:3.9 也改变不了什么。比如尝试采用 Python 官方的基础镜像,纯手工打造一个 AWS Lambda 的镜像,Dockerfile 内容为
# sh-4.2# ls -l /dev |grep shm
drwxrwxrwt 2 root root 40 May 26 17:50 shm
1FROM python:3.9-slim<br/>
2COPY lambda_function.py ./
3RUN pip install --no-cache-dir awslambdaric<br/>
4ENTRYPOINT [ "python", "-m", "awslambdaric", "lambda_function.lambda_handler" ]发布后测试 Lambda 仍然是一样的问题,看来 AWS Lambda 才不在乎在 Docker 镜像中有没有 /dev/shm 目录,继续较真,在 lambda_function.py 中加上代码
1print(os.listdir("/dev"))['urandom', 'null', 'full', 'zero', 'random', 'stderr', 'stdin', 'stdout']确实没有
/dev/shm, 跟是否有 Docker 镜像部署 Lambda 无关,而用 docker 命令直接进到该容器的中看到的 "/dev" 下的内容却是['console', 'core', 'stderr', 'stdout', 'stdin', 'fd', 'ptmx', 'urandom', 'zero', 'tty', 'full', 'random', 'null', 'shm', 'mqueue', 'pts'](试图在构建镜像是 chmod -R 777 /dev, 然后 Python 代码中用 os.mkdirs("/dev/shm") 还是没权限创建目录的)
继续大胆的去试,既然 Python 内置的 multiprocessing 不行,那么试下 multiprocess 如何,安装用
pip install multiprocess然后在 Lambda 中把 multiprocessing.Pool 替换成 multiprocess.Pool, 部署,测试,同样的错误
[Errno 38] Function not implemented同样是依赖于 /dev/shm 目录,其实在 Python 源文件可找到
/dev/shm, 在 multiprocess 也是用的 /dev/shm试过了 loky 组件也没用,看来只能退回到使用最原始的 Process 来创建子进程了, 通过进程间的管道(Pipe)来传递结果数据,最终在 AWS Lambda 要使用 Python 进程的话,只能是
1import os
2from multiprocessing import Process, Pipe
3
4def task(x, conn):
5 result = f'pid: {os.getpid()}, value: {x*x}'
6 conn.send(result)
7 conn.close()
8
9def lambda_handler(event, context):
10 processes = []
11 parent_connections = []
12
13 for i in [2, 3]:
14 parent_conn, child_conn = Pipe()
15 parent_connections.append(parent_conn)
16
17 process = Process(target=task, args=(i, child_conn,))
18 processes.append(process)
19
20 # start all processes
21 for process in processes:
22 process.start()
23
24 # make sure that all processes have finished
25 for process in processes:
26 process.join()
27
28 value = []
29 for parent_connection in parent_connections:
30 value.append(parent_connection.recv())
31
32 return value[parent_conn 和 child_conn 是父子进程间通信的管道,它们之间是联通了的,类似于 Java 的 PipedInputStream 和 PipedOutputStream. 子进程可用 child_conn.send(result) 传递任何类型的数据,在父进程端用 parent_conn.recv() 获得相同的数据。
"pid: 19, value: 4",
"pid: 20, value: 9"
]
这是目前经过一番探索之后所知道的唯一可用在 AWS Lambda 中启动 Python 子进程的方法。
May, 12, 2023 注:除了 join() 之外还能用 wait 方法来等待进程的结束。wait 作用到 connection 列表的话,只要其中有 connection 是 ready 的话就会返回,所以以反复检查。
1from multiprocessing.connection import wait
2
3while parent_connections:
4 for parent_conn in wait(parent_connections):
5 try:
6 print(parent_conn.recv()
7 except EOFError:
8 readers.remove(parent_conn)链接:
- Parallel Processing in Python with AWS Lambda
- Understanding Multiprocessing in AWS Lambda with Python
- Python 子进程与子进程池的应用
- Halving our AWS Lambda bill with parallel processing in Python
- AWS Lambda Memory Vs CPU configuration
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。