HDFS 分布式文件系统的搭建与使用
HDFS(Hadoop Distributed File System) 是 Hadoop 的一个重要的模块,有点像磁盘阵列一样,不过它构建的是分布式网络文件系统。由于数据块从多个节上存取,也就能突破单点的网络带宽和硬件资源的限制而获得更好的性能; 能处理更大的数据,和克服单点故障的问题。许多公司正在使用 HDFS 构建自己的分布式文件系统,还比支持它的应用有 Spark, Presto, Hive, HBase, Zeppelin 等。
本文将实战自己搭建一个 HDFS 分布式文件系统,体验最基本的 HDFS 文件操作,看看它是如何分布文件块,以及如何进行冗余容错的。
本次实战环境:
我们将使用 4 个 Vagrant 虚拟机,其中一个为 NameNode, 其余为 DataNode。HDFS 沿袭了传统的 Master/Slave 系统架构,但因目前像传统的计算机名词 PC, CRT 被恶意使用的当下,Master/Slave 相应的更名为 NameNode 和 DataNode。在通常的系统中, Master 兼具协调与数据存储的功能,而 Slave 只存储数据,而 HDFS 的 NameNode 仅保管文件的元信息,数据块存储在 DataNode 中。
我们在虚拟机中的所采用的系统为 Ubuntu 22.04 LTS 版, 它们全部定义在同一个 Vagrantfile 文件中,使用固定的私有 IP 地址。所以虚拟机之间,虚拟机与宿主机之间是互通的,我们从宿主机发起的访问即模拟了远程访问 HDFS 集群的效果。
所以虚拟机启动后所有的系统如下
Vagrantfile 文件内容
然后启动所有的虚拟机
Hadoop 当前(2022-10-08)版本为 3.3.4, 于 2022 年 8 月 8 日发布,源码需用 Java 8 来编译,但编译后可运行在 Java 11 下。官方的 Hadoop Java Versions 中说的是
因此我们先 ssh 登陆 hdfs-nn01,安装 JDK 和 Hadoop
除了会用到 $HADOOP_HOME/bin 下的命令外,在 $HADOOP_HOME/sbin 目录中还有许多有用的脚本,比如启动单机的 HDFS 只要在格式化 HDFS 文件系统后执行 $HADOOP_HOME/sbin/start-dfs.sh 命令,还包括 yarn 等的操作。
如果总是用 vagrant 用户来启动, hadoop 的 PATH 也可以配置在用户目录中的 .bashrc 或 .bash_profile 当中
编辑 /opt/hadoop-3.3.4/etc/hadoop/hadoop-env.sh, 添加导出 JAVA_HOME 的代码
该文件默认为空的 <configuration> 内容,这里我们配置 fs.defaultFS 先用 IP 地址,后面加入 DataNode 时必须用 hostname,随后再说明。
然后执行
查看启动的进程与端口号(需先用 sudo apt install net-tools 安装才能使用 netstat 命令)
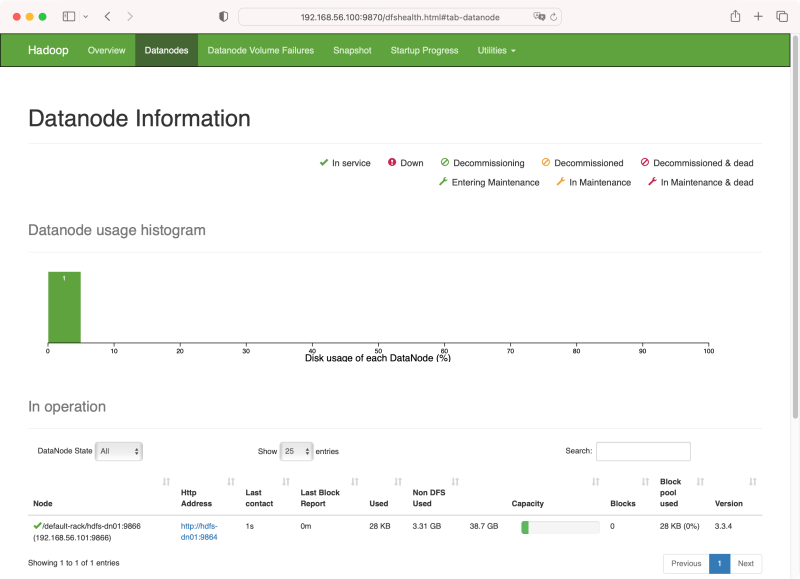
9870 是 web-ui 的端口号,用 http://192.168.56.100:9870 就能在浏览器中打开管理界面, 8020 用于标识一个 hdfs 文件系统。打开 http://192.168.56.100:9870/dfshealth.html#tab-datanode
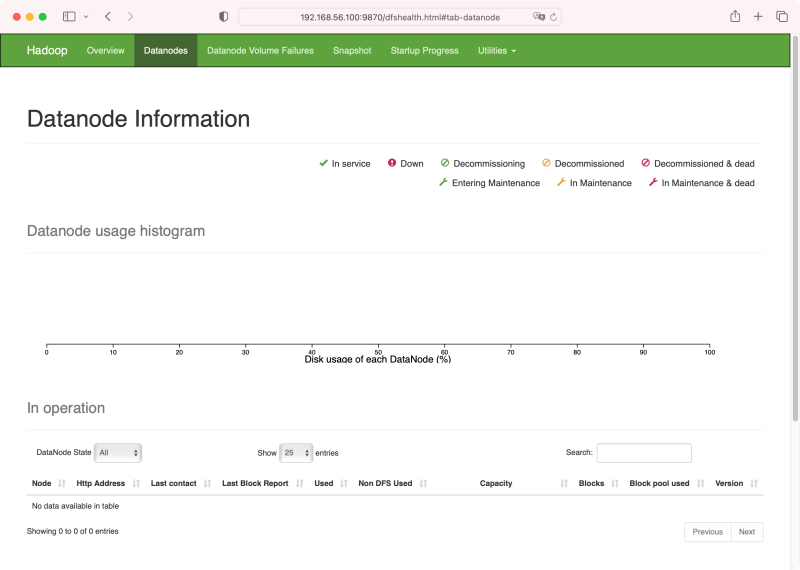 现在还没有 DataNode,现在 hdhs-nn01 节点上尝试一下
现在还没有 DataNode,现在 hdhs-nn01 节点上尝试一下
这时候浏览器中访问 http://192.168.56.100:9870/dfshealth.html#tab-datanode, 将能看到在 master 节点时同时启动的 datanode
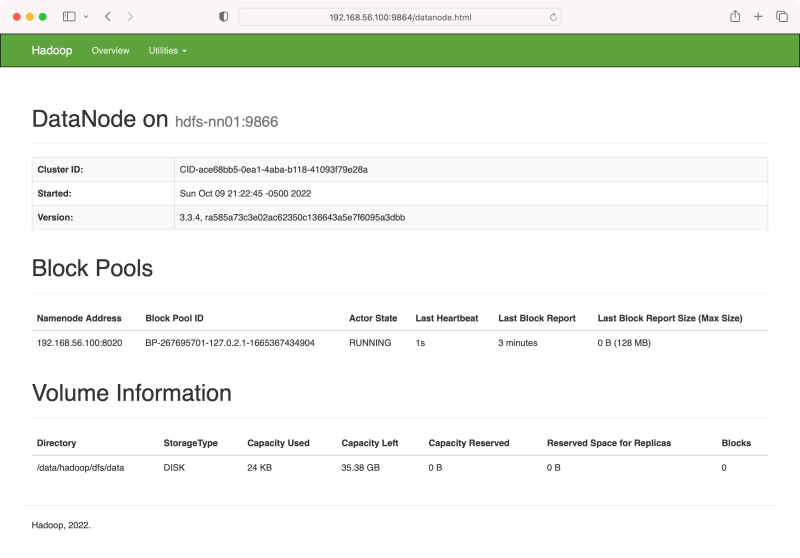
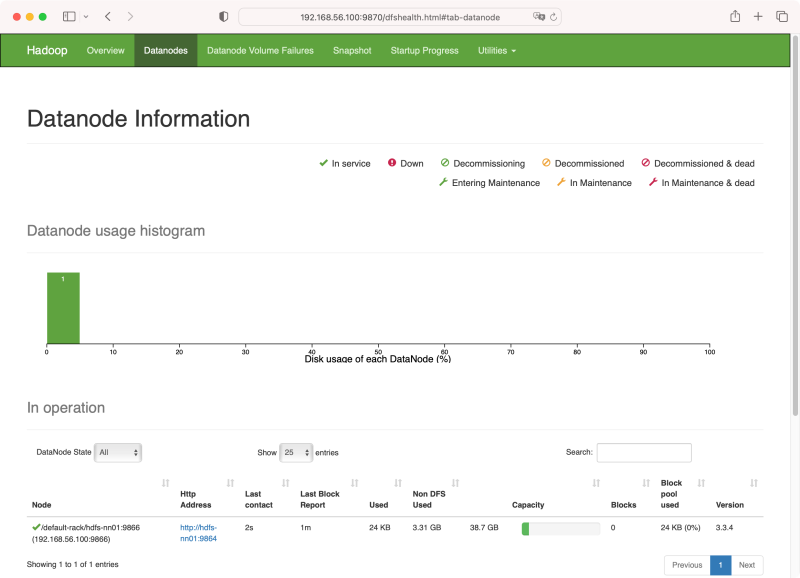 也可以访问 DataNode 的 web-ui 界面,这里显示的是 http://hdfs-master:9864(这是第一个要使用 hostname 的地方), 但由于我们未配置 DNS 或 /etc/hosts 文件,所以需要用 IP 地址来访问,如 http://192.168.56.100:9864/, 看到的是
也可以访问 DataNode 的 web-ui 界面,这里显示的是 http://hdfs-master:9864(这是第一个要使用 hostname 的地方), 但由于我们未配置 DNS 或 /etc/hosts 文件,所以需要用 IP 地址来访问,如 http://192.168.56.100:9864/, 看到的是
 现在作为一个单节点的 HDFS 系统,我们可以上传文件,可用命令或 web-ui http://192.168.56.100:9870/explorer.html#, 界面如下
现在作为一个单节点的 HDFS 系统,我们可以上传文件,可用命令或 web-ui http://192.168.56.100:9870/explorer.html#, 界面如下
 目前为空。本文我们用基本的
目前为空。本文我们用基本的
等等,
因此我们需先创建好
注意到我们执行
还记得我们之前在 $HADOOP_HOME/etc/hadoop/core-site.xml 中配置了 fs.defaultFS 吗?因而在 master 节点中默认就是对 hdfs://192.168.56.100:8020 文件系统进行的操作。
明白了如何指定远程 HDFS 集群后,我们就能够在任意安装了 Hadoop 的机器上执行
试着在 hdfs-nn01 节点中停掉 datanode, 命令
进到第一个 DataNode 节点,现在用
现在尝试在 hdfs-dn01 节点上启动 DataNode
但是在 http://192.168.56.100:9870/dfshealth.html#tab-datanode 没有显示出任何 DataNode 信息。
这时候就要查看日志文件了,打开
我们在 macOS 宿主机下对 HDFS 进行远程操作,先把 hdfs dfs 命令简化一下
修改 $HADOOP/etc/hadoop/log4j.properties, 添加一行
再修改 $HADOOP/etc/hadoop/core-site.xml,改成
检查一下是否连接
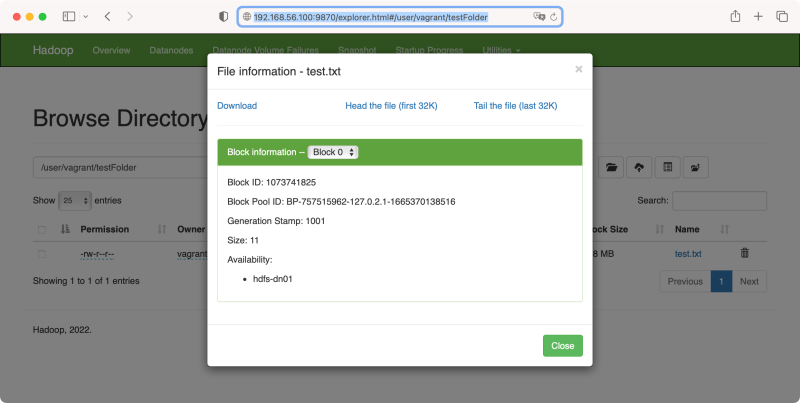 查看 hdfs-dn01 上的数据文件信息
查看 hdfs-dn01 上的数据文件信息
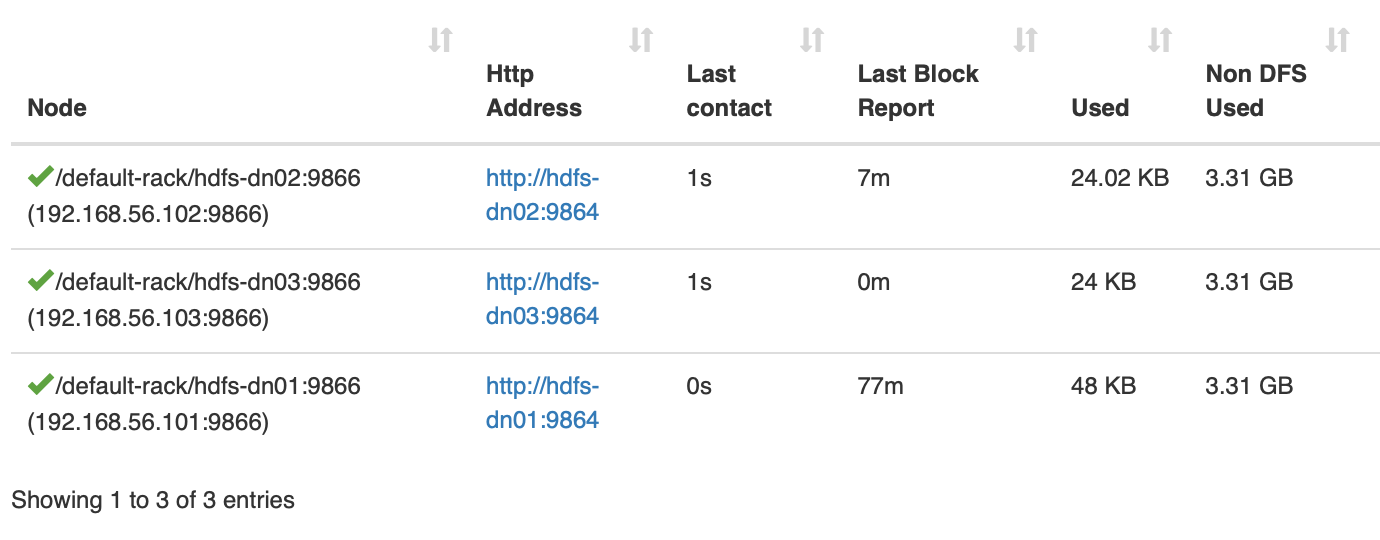
再上一个 DataNode hdfs-dn02, 还是相同的操作与配置,还要在 hdfs-nn01 上的 /etc/hosts 中加一条
现在上来两个 DataNode 了
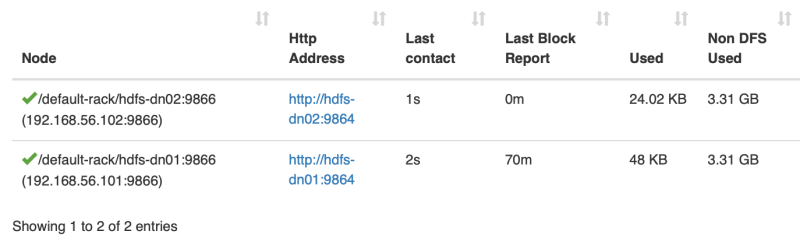 数据分布到了两个节点上了
数据分布到了两个节点上了
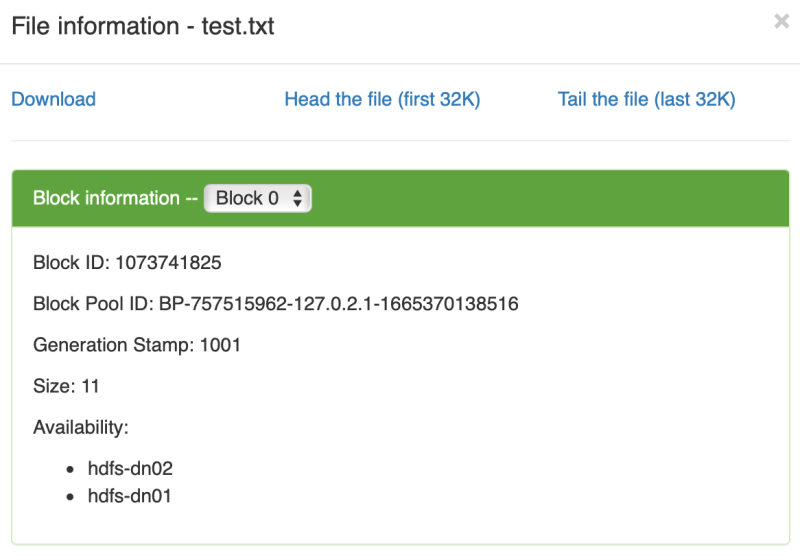 在 hdfs-dn02 上查看文件
在 hdfs-dn02 上查看文件
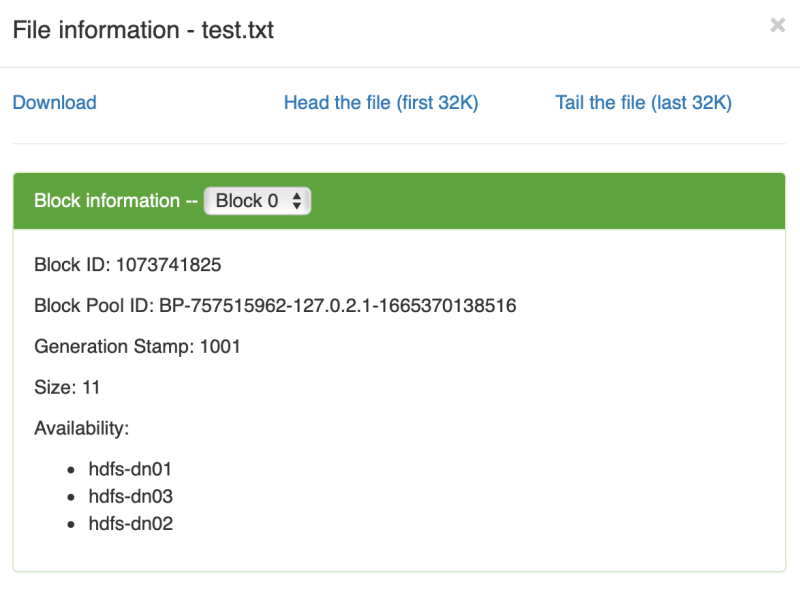
 文件信息
文件信息
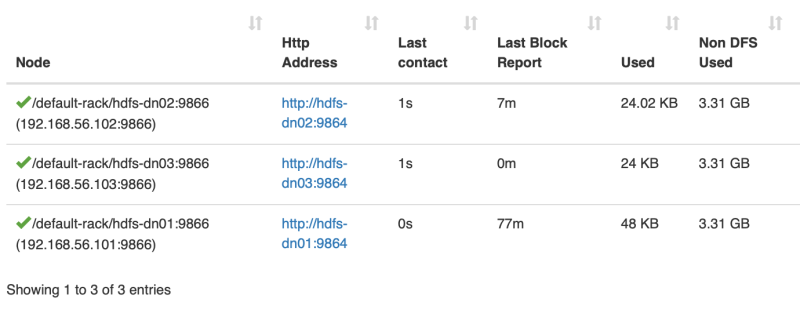
 数据块分布到了三个节点
数据块分布到了三个节点
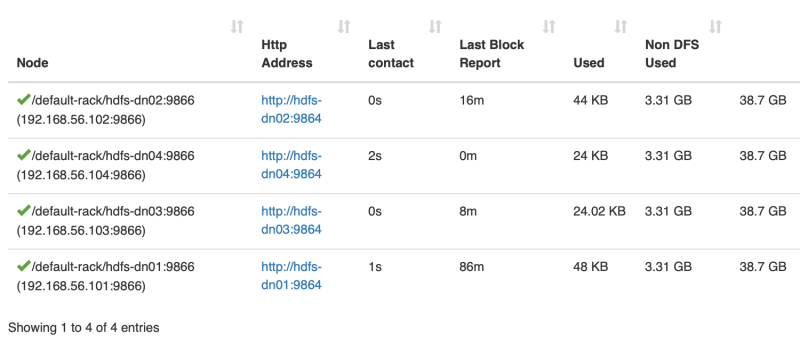 文件内容分布
文件内容分布
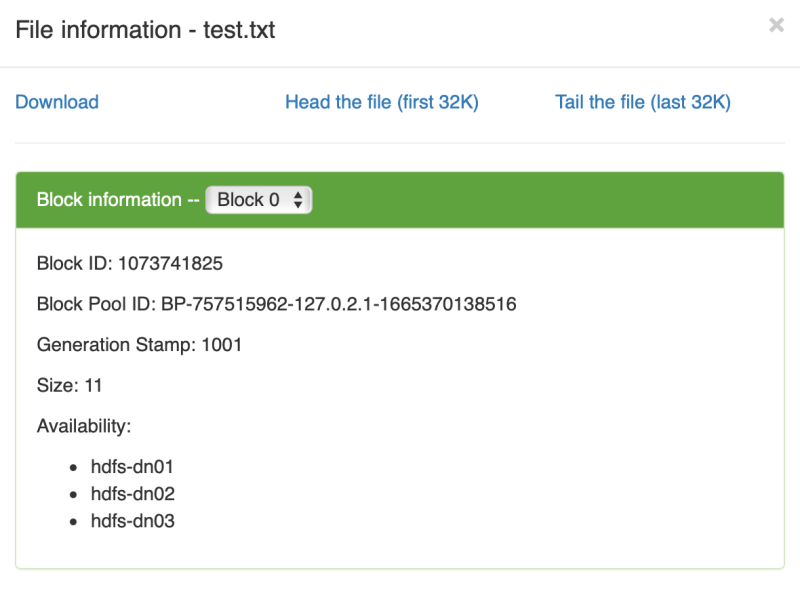 终于不再扩散,默认的冗余存储方式是三份
终于不再扩散,默认的冗余存储方式是三份
再创建一个新文件
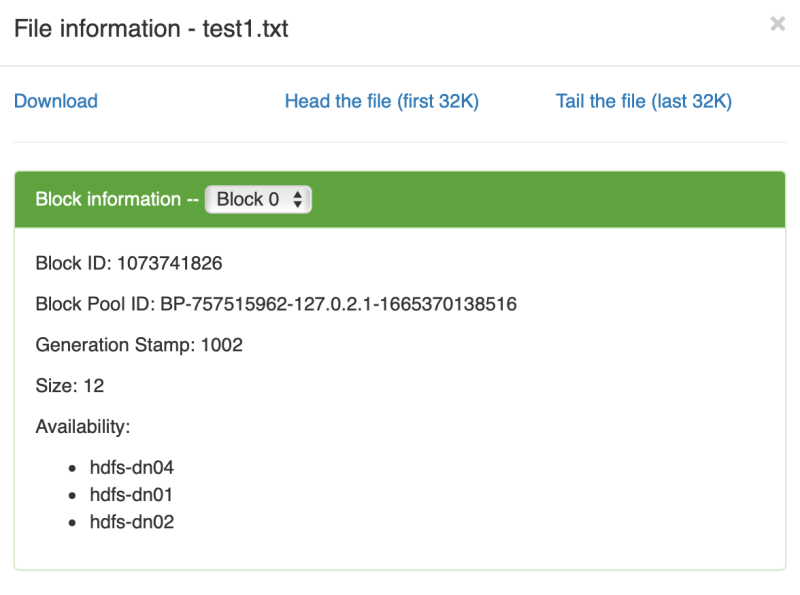 分布在不同的三个数据节点上
分布在不同的三个数据节点上
测试一个大文件, 也不用太大,1.2 GB 的 CSV 文件
上传完后

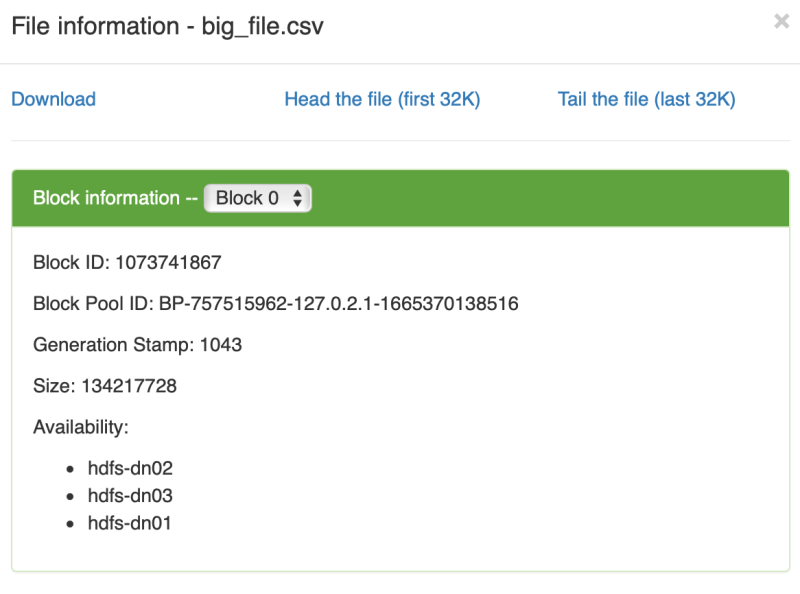 数据块大小为 128M, 数据分布在三个数据节点上,而实际上在所有的四他数据节点上都占用了 2-3 百M的数据大小,似乎每个节点上都有 big_file.csv 的数据文件
数据块大小为 128M, 数据分布在三个数据节点上,而实际上在所有的四他数据节点上都占用了 2-3 百M的数据大小,似乎每个节点上都有 big_file.csv 的数据文件
四个节点上都有许多的数据块文件,每个数据块大小限制为 128M。文件信息中说的在 hdfs-dn04 上没有数据,那就专门窥探一下 hdfs-dn04 的数据目录
这是一个 csv 纯文本文件,所以可以直接查看一下它在 hdfs-dn04 节点中的数据块文件的内容
 128M 的数据块是属于大文件的,其中
128M 的数据块是属于大文件的,其中
这涉及到文件块分布的负载均衡的算法,从现在 4 个数据节点,副本数为 3 的情况,从任何两个数据节点都能拼凑出完整的 big_file.csv 文件,换句话说就是数据节点坏一,坏两个都没问题,文件还能正确读取出来,这就是 HDFS 的容错性。
从 Hadoop HDFS - Hadoop Distributed File System 一文中找了一张图
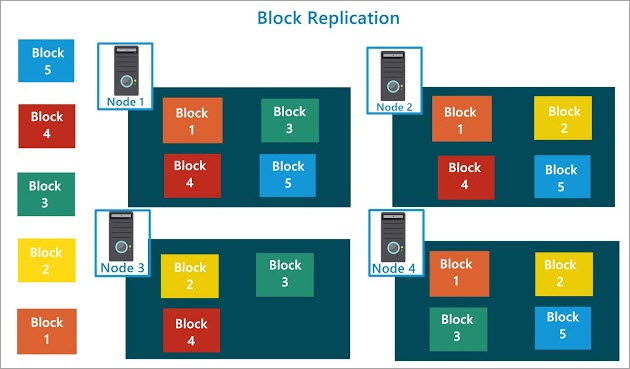 HDFS 的均衡策略和副本个数实现了磁盘阵列的效果,他们实际用途也差不多。
HDFS 的均衡策略和副本个数实现了磁盘阵列的效果,他们实际用途也差不多。
如果在 HDFS 集群中缩减了 DataNode 的数目,先前该节点上的数据应该会转移到别的节点上去。后又扩充了更多的 DataNode, 基于访问性能的考虑,HDFS 应该会优化数据块的分布,对数据块进行 Rebalance 操作移动数据。
关于 /etc/hosts 在 Vagrant 中有更好的解决办法
vagrant plugin install vagrant-hostsupdater 可以使用 host 的 /etc/hosts 中的配置,并且每个 vagrant 虚拟机都会向 /etc/hosts 中注册自己,这样就不需要在 NameNode 中编辑 /etc/hosts 文件。
另外,刚看到一个 JuiceFS 文件系统也很好玩,比如挂载一个 redis 缓存,以文件系统的方式来访问
链接:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文将实战自己搭建一个 HDFS 分布式文件系统,体验最基本的 HDFS 文件操作,看看它是如何分布文件块,以及如何进行冗余容错的。
本次实战环境:
- macOS Big Sur 11.7, VirtualBox 6.1.32 r149290, Vagrant 2.2.19
- Vagrant Ubuntu 22.04 LTS 虚拟机
- Open JDK 8
- Hadoop 3.3.4
我们将使用 4 个 Vagrant 虚拟机,其中一个为 NameNode, 其余为 DataNode。HDFS 沿袭了传统的 Master/Slave 系统架构,但因目前像传统的计算机名词 PC, CRT 被恶意使用的当下,Master/Slave 相应的更名为 NameNode 和 DataNode。在通常的系统中, Master 兼具协调与数据存储的功能,而 Slave 只存储数据,而 HDFS 的 NameNode 仅保管文件的元信息,数据块存储在 DataNode 中。
我们在虚拟机中的所采用的系统为 Ubuntu 22.04 LTS 版, 它们全部定义在同一个 Vagrantfile 文件中,使用固定的私有 IP 地址。所以虚拟机之间,虚拟机与宿主机之间是互通的,我们从宿主机发起的访问即模拟了远程访问 HDFS 集群的效果。
注:关于 Vagrant 的日常基本操作请参考 Vagrant 简介与常用操作及配置。另外,HDFS 还可配置更多功能的 Secondary NameNode, Checkpoint Node, Backup Node, 这些是对 HDFS 集群的增强,不在本文的研究范围。我们本着不提供傻瓜教程,不一次做对的原则,凭着直觉去蹚浑水才能积累到真正属于自己的实战经验。
所以虚拟机启动后所有的系统如下
| IP | Hostname |
| 192.168.56.100 | hdfs-nn01 |
| 192.168.56.101 | hdfs-dn01 |
| 192.168.56.102 | hdfs-dn02 |
| 192.168.56.103 | hdfs-dn03 |
Vagrantfile 文件内容
1Vagrant.configure("2") do |config|
2 config.vm.box = "ubuntu/jammy64"
3
4 config.vm.define "hdfs-nn01" do |nn01|
5 nn01.vm.network "private_network", ip: "192.168.56.100"
6 nn01.vm.hostname = "hdfs-nn01"
7 end
8
9 config.vm.define "hdfs-dn01" do |dn01|
10 dn01.vm.network "private_network", ip: "192.168.56.101"
11 dn01.vm.hostname = "hdfs-dn01"
12 end
13 config.vm.define "hdfs-dn02" do |dn02|
14 dn02.vm.network "private_network", ip: "192.168.56.102"
15 dn02.vm.hostname = "hdfs-dn02"
16 end
17 config.vm.define "hdfs-dn03" do |dn03|
18 dn03.vm.network "private_network", ip: "192.168.56.103"
19 dn03.vm.hostname = "hdfs-dn03"
20 end
21
22end然后启动所有的虚拟机
vagrant up查看虚拟机状态
这时候从宿主机上也可 ping 通以上四个虚拟机的 IP 地址 192.168.56.xxx。需要 ssh 进入某一个虚拟机的话,只要运行命令1➜ vagrant vagrant global-status 2id name provider state directory 3-------------------------------------------------------------------------- 44d40803 hdfs-nn01 virtualbox running /Users/yanbin/Workspaces/vagrant 5c76ef1d hdfs-dn01 virtualbox running /Users/yanbin/Workspaces/vagrant 621a8194 hdfs-dn02 virtualbox running /Users/yanbin/Workspaces/vagrant 77f52954 hdfs-dn03 virtualbox running /Users/yanbin/Workspaces/vagrant
vagrant ssh <name>, 如要进入 hdfs-nn01 虚拟机,命令是vagrant ssh hdfs-nn01以上的 /Users/yanbin/Workspaces/vagrant 是用来在宿主机与虚拟机之间共享文件的目录,它映射到虚拟机的
/vagrant 目录,所以以上四个虚拟机的 /vagrant 都是指向宿主机的同一个目录。Hadoop 当前(2022-10-08)版本为 3.3.4, 于 2022 年 8 月 8 日发布,源码需用 Java 8 来编译,但编译后可运行在 Java 11 下。官方的 Hadoop Java Versions 中说的是
Apache Hadoop 3.3 and upper supports Java 8 and Java 11 (runtime only), 目前有一个 Ticket 是关于支持用 Java 11 编译 Hadoop 3.3 的。所以最后还是选择用 Java 8。从 hdfs-nn01 节点开始
先以 hdfs-nn01 为起点逐步配置,启动一个 NameNode,再尝试在 hdfs-nn01 起动 DataNode,再体验 HDFS 文件的存取。然后再渐进的使用,配置,添加真正的 DataNode,并查看文件块是如何分布的。因此我们先 ssh 登陆 hdfs-nn01,安装 JDK 和 Hadoop
$ vagrant ssh hdfs-nn01进到 hdfs-nn01 虚拟机的 shell, 以下命令在 hdfs-nn01 虚拟机中执行
vagrant@hdfs-nn01:~$ sudo apt update编辑 hdfs-nn01 中的 /etc/profile 文件,并加上以下两行
vagrant@hdfs-nn01:~$ sudo apt install openjdk-8-jdk -y
vagrant@hdfs-nn01:~$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
vagrant@hdfs-nn01:~$ sudo tar xzvf hadoop-3.3.4.tar.gz -C /opt
vagrant@hdfs-nn01:~$ sudo mkdir -p /data/hadoop
vagrant@hdfs-nn01:~$ sudo chown -R vagrant:vagrant /data/hadoop /opt/hadoop-3.3.4
export PATH=/opt/hadoop-3.3.4/bin:$PATHsource /etc/profile 或重新用 vagrant ssh 登陆后就能使用 hdfs 命令了。
除了会用到 $HADOOP_HOME/bin 下的命令外,在 $HADOOP_HOME/sbin 目录中还有许多有用的脚本,比如启动单机的 HDFS 只要在格式化 HDFS 文件系统后执行 $HADOOP_HOME/sbin/start-dfs.sh 命令,还包括 yarn 等的操作。
如果总是用 vagrant 用户来启动, hadoop 的 PATH 也可以配置在用户目录中的 .bashrc 或 .bash_profile 当中
编辑 /opt/hadoop-3.3.4/etc/hadoop/hadoop-env.sh, 添加导出 JAVA_HOME 的代码
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64JAVA_HOME 也可以像前面 PATH 一样配置在全局或用户的 profile 文件中。还可以配置一个辅助的 HADOOP_HOME 指向 /opt/hadoop-3.3.4 目录,我们随后用 $HADOOP_HOME 指代该实际的目录。
配置 core-site.xml 文件
编辑文件 $HADOOP_HOME/etc/hadoop/core-site.xml, 内容如下 1<configuration>
2 <property>
3 <name>fs.defaultFS</name>
4 <value>hdfs://192.168.56.100:8020</value>
5 </property><br/><br/>
6 <property>
7 <name>hadoop.tmp.dir</name>
8 <value>/data/hadoop</value>
9 </property>
10</configuration>该文件默认为空的 <configuration> 内容,这里我们配置 fs.defaultFS 先用 IP 地址,后面加入 DataNode 时必须用 hostname,随后再说明。
注:以上水平线之间的操作在后面的每个 DataNode 节点中都是相同的在 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 中可配置每个文件块副本的个数(默认为 3), 和相应的 Secondary NameNode 的地址。Secondary NameNode 节点的作用并非 NameNode 的镜像,而是协助 NameNode 完成 fsimage 和 edit logs 的合并操作。
然后执行
vagrant@hdfs-nn01:~$ hdfs namenode -format hdfs-cluster第一次启动 namenode 或 datanode 都会提示创建日志目录,它同时告诉了我们日志信息要去哪里查看,只要感觉到哪里不对劲就到 /opt/hadoop-3.3.4/logs 目录下去查日志。
vagrant@hdfs-nn01:~$ hdfs --daemon start namenode
WARNING: /opt/hadoop-3.3.4/logs does not exist. Creating.
查看启动的进程与端口号(需先用 sudo apt install net-tools 安装才能使用 netstat 命令)
1vagrant@hdfs-nn01:~$ netstat -ltnp |grep java
2(Not all processes could be identified, non-owned process info
3 will not be shown, you would have to be root to see it all.)
4tcp 0 0 192.168.56.100:8020 0.0.0.0:* LISTEN 6295/java
5tcp 0 0 0.0.0.0:9870 0.0.0.0:* LISTEN 6295/java 现在还没有 DataNode,现在 hdhs-nn01 节点上尝试一下
现在还没有 DataNode,现在 hdhs-nn01 节点上尝试一下 hdfs dfs 命令vagrant@hdfs-nn01:~$ hdfs dfs -df在只有 NameNode 的情况下可以创建目录,但无法存储文件。这也就证明了文件元信息是存储在 NameNode 中,数据块存在别处。我们随后把 /user/vagrant 目录删除掉
Filesystem Size Used Available Use%
hdfs://192.168.56.100:8020 0 0 0 NaN%
vagrant@hdfs-nn01:~$ hdfs dfs -mkdir -p /user/vagrant
vagrant@hdfs-nn01:~$ echo "Hello HDFS" > test.txt
vagrant@hdfs-nn01:~$ hdfs dfs -put test.txt /user/vagrant
2022-10-10 02:11:24,282 WARN hdfs.DataStreamer: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/vagrant/test.txt._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2315)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2960)
.......
vagrant@hdfs-nn01:~$ hdfs dfs -rm -R /user在 hdfs-nn01 节点中直接启动 datanode, 在不涉到其他节点的情况下实现一个伪集群的 HDFS, 命令如下
Deleted /user
vagrant@hdfs-nn01:~$ hdfs --daemon start datanode再查看启动的里程与端口号
1vagrant@hdfs-nn01:~$ netstat -ltnp |grep java
2(Not all processes could be identified, non-owned process info
3 will not be shown, you would have to be root to see it all.)
4tcp 0 0 192.168.56.100:8020 0.0.0.0:* LISTEN 6295/java
5tcp 0 0 0.0.0.0:9867 0.0.0.0:* LISTEN 6993/java
6tcp 0 0 0.0.0.0:9866 0.0.0.0:* LISTEN 6993/java
7tcp 0 0 0.0.0.0:9864 0.0.0.0:* LISTEN 6993/java
8tcp 0 0 0.0.0.0:9870 0.0.0.0:* LISTEN 6295/java
9tcp 0 0 127.0.0.1:46129 0.0.0.0:* LISTEN 6993/java这时候浏览器中访问 http://192.168.56.100:9870/dfshealth.html#tab-datanode, 将能看到在 master 节点时同时启动的 datanode
 也可以访问 DataNode 的 web-ui 界面,这里显示的是 http://hdfs-master:9864(这是第一个要使用 hostname 的地方), 但由于我们未配置 DNS 或 /etc/hosts 文件,所以需要用 IP 地址来访问,如 http://192.168.56.100:9864/, 看到的是
也可以访问 DataNode 的 web-ui 界面,这里显示的是 http://hdfs-master:9864(这是第一个要使用 hostname 的地方), 但由于我们未配置 DNS 或 /etc/hosts 文件,所以需要用 IP 地址来访问,如 http://192.168.56.100:9864/, 看到的是  现在作为一个单节点的 HDFS 系统,我们可以上传文件,可用命令或 web-ui http://192.168.56.100:9870/explorer.html#, 界面如下
现在作为一个单节点的 HDFS 系统,我们可以上传文件,可用命令或 web-ui http://192.168.56.100:9870/explorer.html#, 界面如下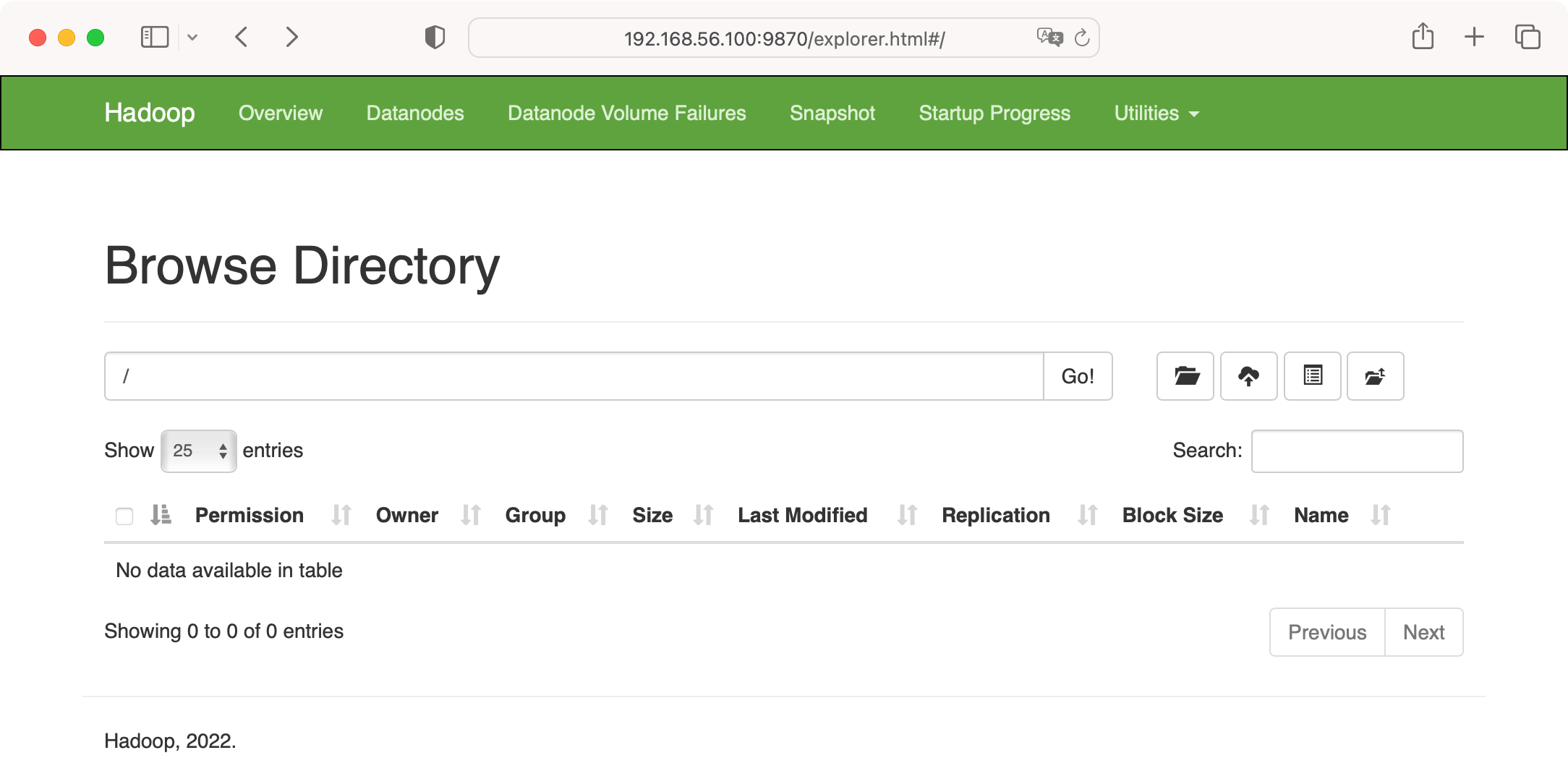 目前为空。本文我们用基本的
目前为空。本文我们用基本的 hdfs dfs 命令来操作。hdfs dfs 后面的参数基本就是我们在 Linux shell 的常用命令前加个 - 参数化,如- hdfs dfs -rm: 删除一个目录
- hdfs dfs -ls: 显示目录中的内容
- hdfs dfs -mkdir: 创建目录
- hdfs dfs -rmdir: 删除目录
- hdfs dfs -put: 上传本地文件或目录到 HDFS 文件系统中
- hdfs dfs -get: 从 HDFS 文件系统中下载文件或目录到本地
- hdfs -df: 显示磁盘空间
等等,
hdfs dfs 能显示出所有支持的命令,命令的参数也可以参考 Linux shell 相应命令的参数,如 hdfs dfs -df -h, hdfs dfs -mkdir -r /a/b/c 等hdfs dfs 操作的起始目录是 /user/<yourName>, 不然会出现下面的错误vagrant@hdfs-nn01:~$ hdfs dfs -ls .这就是为什么我们前面测试在没有 DataNode 节点的情况下先创建了 /user/vagrant 目录的缘故。
ls: `.': No such file or directory vagrant@hdfs-nn01:~$ hdfs dfs -mkdir a
mkdir: `hdfs://192.168.56.100:8020/user/vagrant': No such file or directory
因此我们需先创建好
/user/<yourName> 目录,用 whoami 命令找到 Vagrant 虚拟机中当前用户名是 vagrant, 所以先执行vagrant@hdfs-nn01:~$ hdfs dfs -mkdir -p /user/vagrant这样就没问题了,现在来创建一目录,再上传一个文件
vagrant@hdfs-nn01:~$ hdfs dfs -ls .
vagrant@hdfs-nn01:~$
vagrant@hdfs-nn01:~$ hdfs dfs -mkdir testFolder这里我们是在 hdfs-nn01 节点的 shell 操作的,能把文件上传到 HDFS 文件系统中,那么
vagrant@hdfs-nn01:~$ echo "Hello HDFS" > test.txt
vagrant@hdfs-nn01:~$ hdfs dfs -put test.txt testFolder/
vagrant@hdfs-nn01:~$ hdfs dfs -ls testFolder
Found 1 items
-rw-r--r-- 3 vagrant supergroup 11 2022-10-09 04:02 testFolder/test.txt
vagrant@hdfs-nn01:~$ hdfs dfs -cat testFolder/test.txt
Hello HDFS
hdfs dfs 是如何知道与哪个 HDFS 集群交互呢?注意到我们执行
hdfs dfs 显示出来的帮助后面部分有1Generic options supported are:
2-conf <configuration file> specify an application configuration file
3-D <property=value> define a value for a given property
4-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.还记得我们之前在 $HADOOP_HOME/etc/hadoop/core-site.xml 中配置了 fs.defaultFS 吗?因而在 master 节点中默认就是对 hdfs://192.168.56.100:8020 文件系统进行的操作。
明白了如何指定远程 HDFS 集群后,我们就能够在任意安装了 Hadoop 的机器上执行
hdfs dfs 命令来存取 HDFS 文件系统中的数据了。下面我在自己的 macOS 上下载了 hadoop-3.3.4 后,执行 hdfs dfs 命令的效果➜ ~ export HADOOP_USER_NAME=vagrant配置 HADOOP_USER_NAME=vagrant 就能使用 hdfs dfs 命令访问到先前在 master 节点中上传到
➜ ~ hdfs --loglevel ERROR dfs -fs hdfs://192.168.56.100:8020 -ls testFolder
Found 1 items
-rw-r--r-- 3 vagrant supergroup 11 2022-10-09 21:33 testFolder/test.txt
/user/vagrant 目录中的文件,否则会试图访问 /user/<whoami> 目录, 在 macOS 下 whoami 不再是 vagrant 了。试着在 hdfs-nn01 节点中停掉 datanode, 命令
vagrant@hdfs-master:~$ hdfs --daemon stop datanode然后试图显示文件列表与内容
➜ ~ hdfs --loglevel ERROR dfs -fs hdfs://192.168.56.100:8020 -ls testFolder显示文件列表是没问题,证明文件元信息是保存在 NameNode 上的,而数据内容是在 DataNode 上的。重新启动 master 节点上的 DataNode 后又可以看到文件的内容
Found 1 items
-rw-r--r-- 3 vagrant supergroup 11 2022-10-09 21:33 testFolder/test.txt
➜ ~ hdfs --loglevel ERROR dfs -fs hdfs://192.168.56.100:8020 -cat testFolder/test.txt
cat: Could not obtain block: BP-267695701-127.0.2.1-1665367434904:blk_1073741825_1001 file=/user/vagrant/testFolder/test.txt No live nodes contain current block Block locations: DatanodeInfoWithStorage[192.168.56.100:9866,DS-96a93755-07c8-4ec9-a171-ea0e77c51335,DISK] Dead nodes: DatanodeInfoWithStorage[192.168.56.100:9866,DS-96a93755-07c8-4ec9-a171-ea0e77c51335,DISK]
加入一个实际的 DataNode
在进入该步测试之前,先对当前的 HDFS 集群作一个清理,在 hdfs-nn01 节点上运行如下命令vagrant@hdfs-nn01:~$ hdfs --daemon stop datanode这样能确保有 HDFS 文件系统是干净的,而且在 HDFS 集群中也不再有死了的 DataNode
vagrant@hdfs-nn01:~$ rm -R /data/hadoop/* # 可选
vagrant@hdfs-nn01:~$ hdfs namenode -format hdfs-cluster
vagrant@hdfs-nn01:~$ hdfs --daemon start namenode
进到第一个 DataNode 节点,现在用
vagrant ssh hdfs-dn01 进到该节点的 shell,与在 hdfs-nn01 上节点的相同的基本操作包括- 安装 JDK 8, 下载解压 Hadoop
- 配置 JAVA_HOME 和指向到 /opt/hadoop-3.3.4/bin 目录的 PATH 环境变量
- 创建目录 /data/hadoop 和修改 /data/hadoop 和 /opt/hadoop-3.3.4 的目录所有者
- 配置 core0-site.xml 文件
现在尝试在 hdfs-dn01 节点上启动 DataNode
vagrant@hdfs-dn01:~$ hdfs --daemon start datanode这时候用 netstat 查看到的 Java 进程
1vagrant@hdfs-dn01:~$ netstat -ltnp |grep java
2(Not all processes could be identified, non-owned process info
3 will not be shown, you would have to be root to see it all.)
4tcp 0 0 0.0.0.0:9864 0.0.0.0:* LISTEN 5513/java
5tcp 0 0 0.0.0.0:9867 0.0.0.0:* LISTEN 5513/java
6tcp 0 0 0.0.0.0:9866 0.0.0.0:* LISTEN 5513/java
7tcp 0 0 127.0.0.1:41141 0.0.0.0:* LISTEN 5513/java这时候就要查看日志文件了,打开
/opt/hadoop-3.3.4/logs/hadoop-vagrant-datanode-hdfs-dn01.log看到类似下方的错误信息
2022-10-10 03:14:58,097 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool BP-757515962-127.0.2.1-1665370138516 (Datanode Uuid bd84394d-4384-4d81-82b8-727baa03cb94) service to /192.168.56.100:8020 Datanode denied communication with namenode because hostname cannot be resolved (ip=192.168.56.101, hostname=192.168.56.101): DatanodeRegistration(0.0.0.0:9866, datanodeUuid=bd84394d-4384-4d81-82b8-727baa03cb94, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-a1f2d5ae-b46f-4b96-b0e1-22b518f89676;nsid=643369223;c=1665370138516)原来是 NameNode hdfs-nn01 中无法解析 IP 192.168.56.101 成 hostname, 所以要让 hdfs-dn01 作为 datanode 加入到 namenode 中去的话,必须让 NameNode 能反向解析出该 DataNode 的 IP 地址,于是只要在 hdfs-nn01 节点的 /etc/hosts 中加上一条
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:1147)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.registerDatanode(BlockManager.java:2566)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:4235)
192.168.56.101 hdfs-dn01再回到 hdfs-dn01 上重启 DataNode, 需执行的命令是
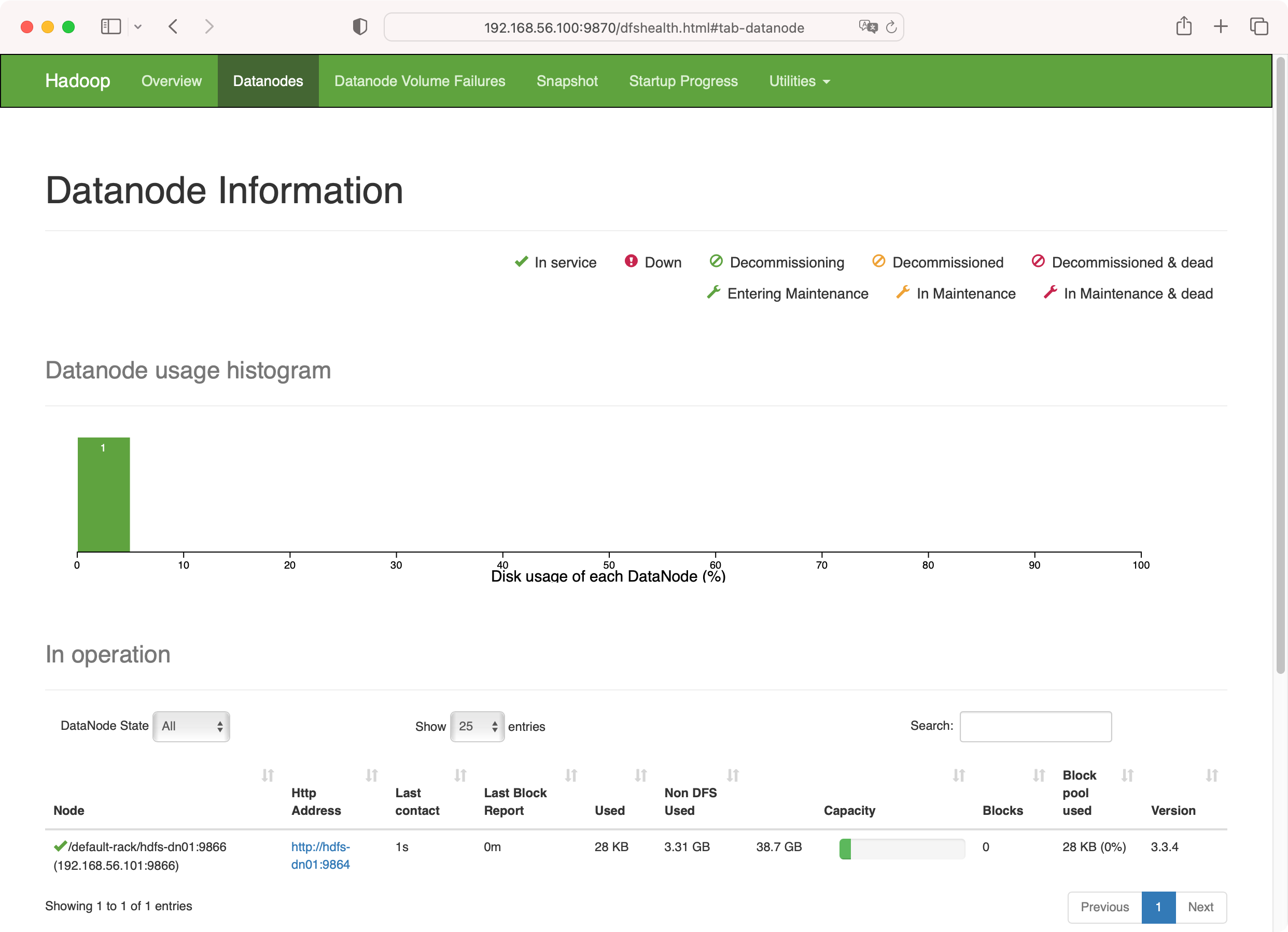
vagrant@hdfs-dn01:~$ hdfs --daemon stop datanode再查看 http://192.168.56.100:9870/dfshealth.html#tab-datanode,就有了 hdfs-dn01 这个数据节点了
vagrant@hdfs-dn01:~$ hdfs --daemon start datanode
观察数据在集群中的分布
目前有了一个接近实际意义上的 HDFS 集群 -- 一个 NameNode 和一个 DataNode, 接下来上传一个文件看它的数据块是如何在 HDFS 的 DataNode 中分布的,其间会往集群中逐步添加更多的数据节点。我们在 macOS 宿主机下对 HDFS 进行远程操作,先把 hdfs dfs 命令简化一下
修改 $HADOOP/etc/hadoop/log4j.properties, 添加一行
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR把执行 hdfs 时的
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable警告信息去掉,也不用加 --loglevel ERROR 参数。因为从官方下载的 Hadoop 二进制版本地库是 32 位的,而 brew install hadoop 安装的 Hadoop 不带本地库,除非下载源码自行编译。
再修改 $HADOOP/etc/hadoop/core-site.xml,改成
1<configuration>
2 <property>
3 <name>fs.defaultFS</name>
4 <value>hdfs://192.168.56.100:8020</value>
5 </property>
6</configuration>检查一下是否连接
➜ ~ hdfs dfs -df上传一个测试文件
Filesystem Size Used Available Use%
hdfs://192.168.56.100:8020 41555521536 32768 37984940032 0%
➜ ~ export HADOOP_USER_NAME=vagrant查看文件信息 http://192.168.56.100:9870/explorer.html#/user/vagrant/testFolder
➜ ~ hdfs dfs -mkdir -p /user/vagrant
➜ ~ hdfs dfs -mkdir testFolder
➜ ~ echo "Hello HDFS" > test.txt
➜ ~ hdfs dfs -put test.txt testFolder/
➜ ~ hdfs dfs -cat testFolder/test.txt
Hello HDFS
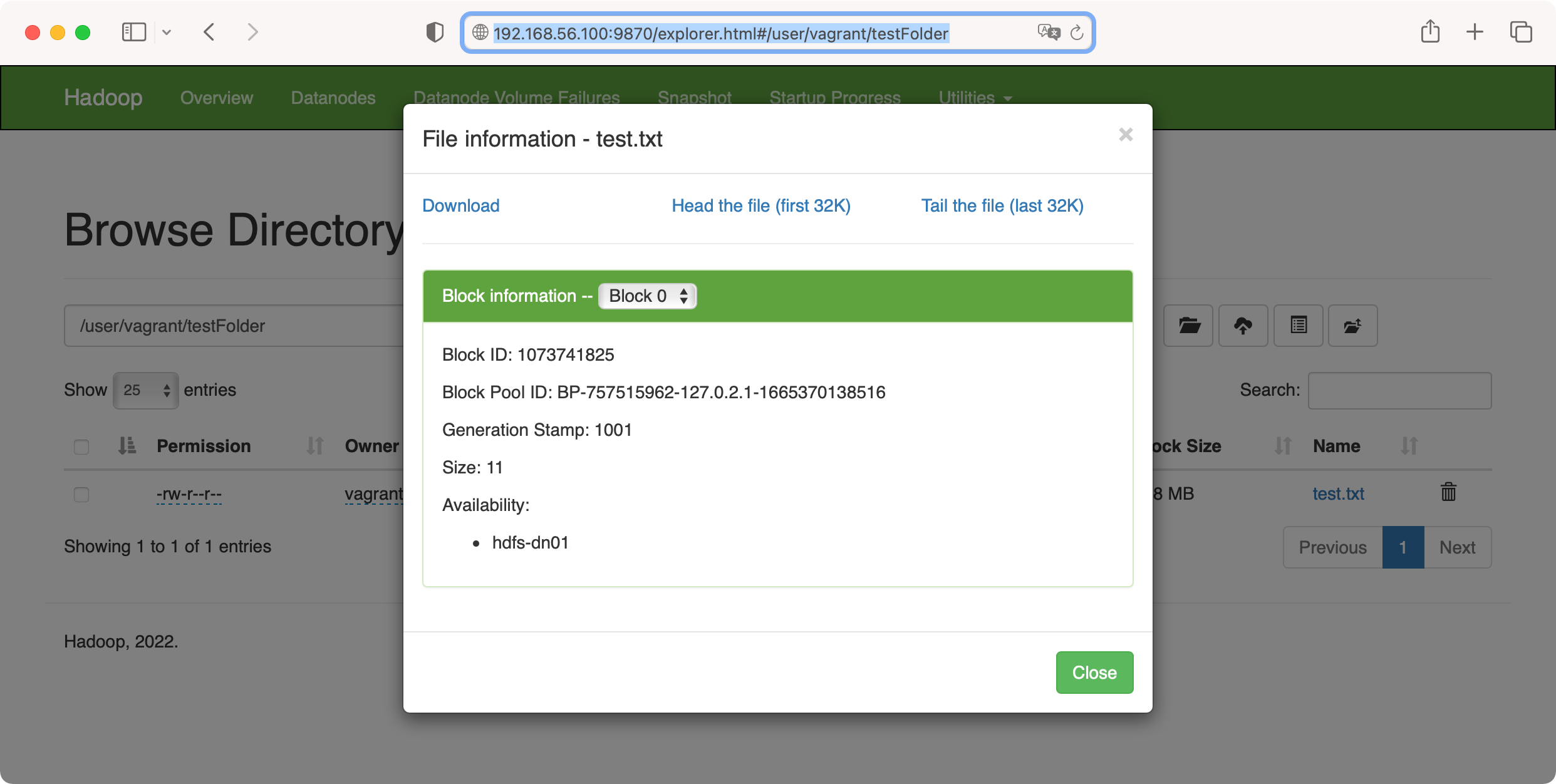 查看 hdfs-dn01 上的数据文件信息
查看 hdfs-dn01 上的数据文件信息vagrant@hdfs-dn01:~$ cat /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0/blk_1073741825在 hdfs-nn01 上没有 /data/hadoop/dfs/data 目录,因为它不存数据
Hello HDFS
再上一个 DataNode hdfs-dn02, 还是相同的操作与配置,还要在 hdfs-nn01 上的 /etc/hosts 中加一条
192.168.56.102 hdfs-dn02再用命令 hdfs dfs --daemon start datanode 启动 datanode 就行
现在上来两个 DataNode 了
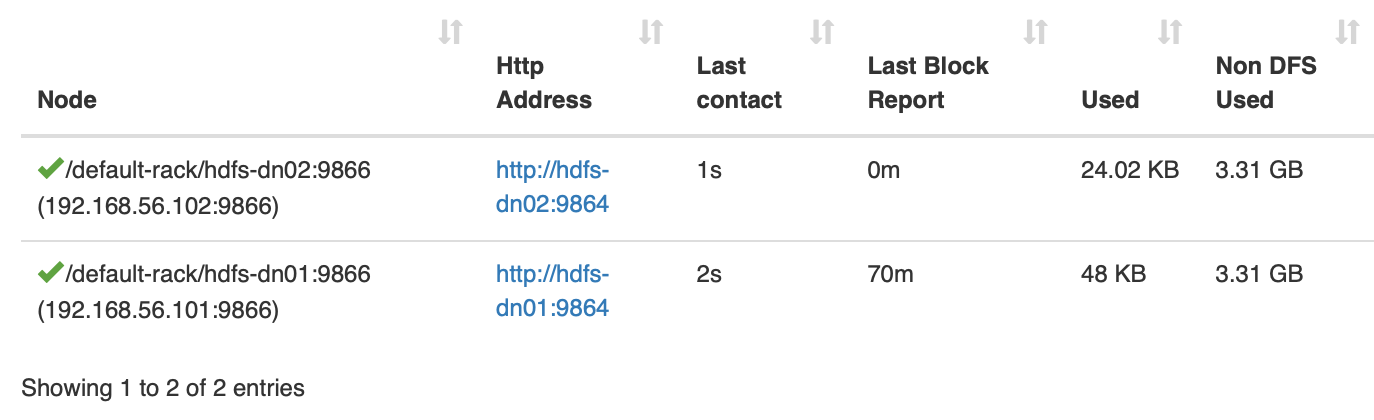 数据分布到了两个节点上了
数据分布到了两个节点上了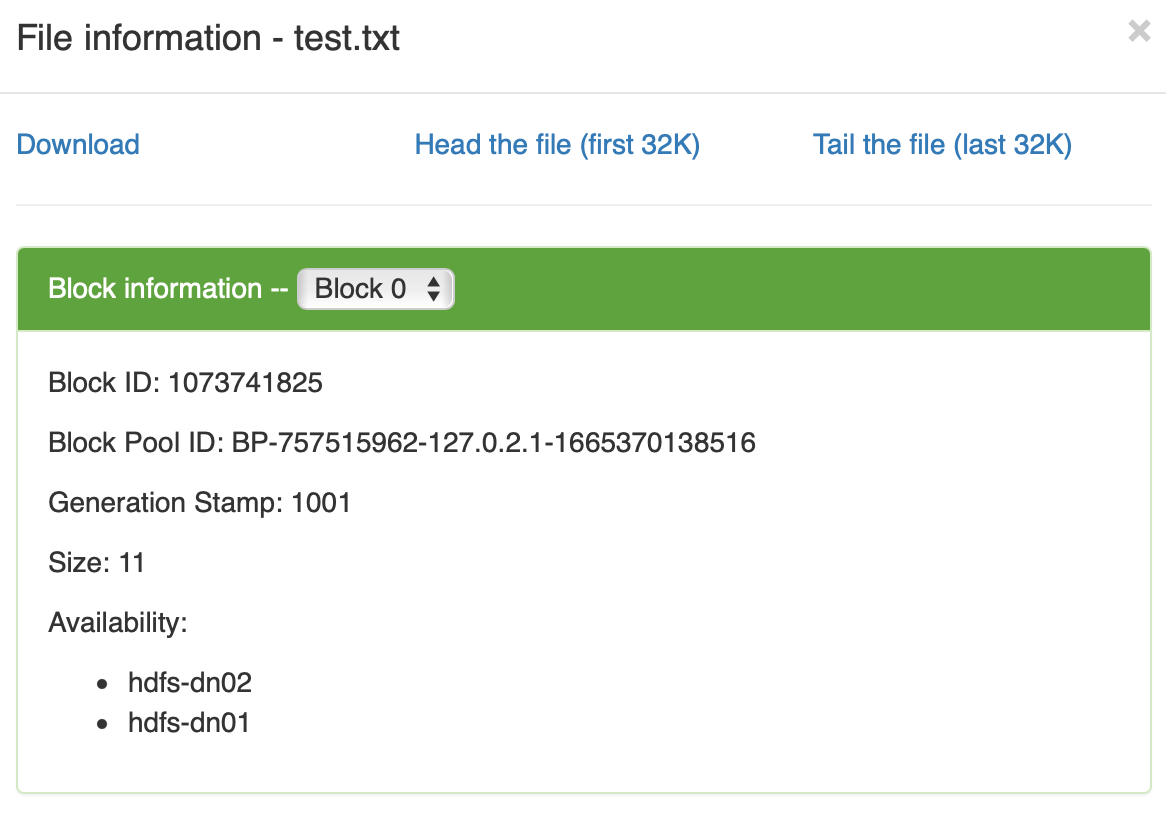 在 hdfs-dn02 上查看文件
在 hdfs-dn02 上查看文件vagrant@hdfs-dn02:~$ cat /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0/blk_1073741825再上一个 hdfs-dn03 节点
Hello HDFS
 文件信息
文件信息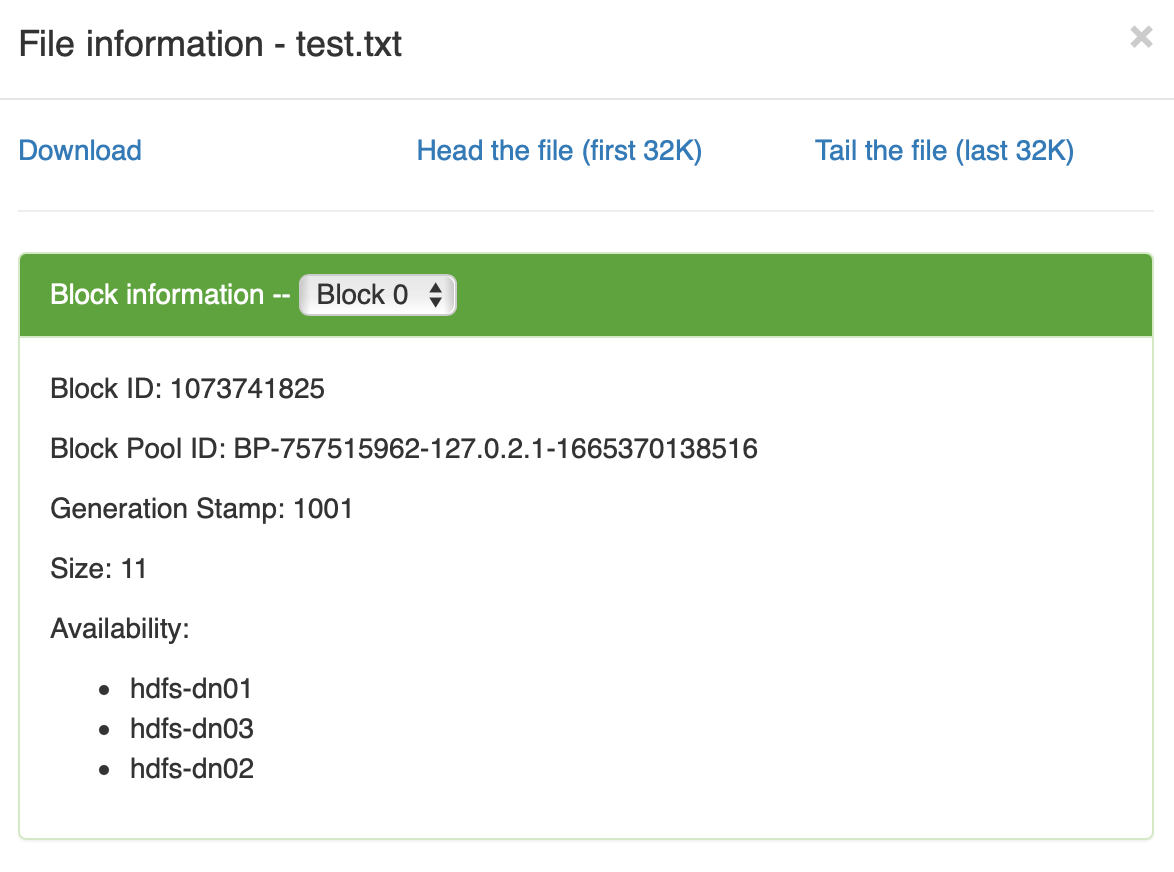 数据块分布到了三个节点
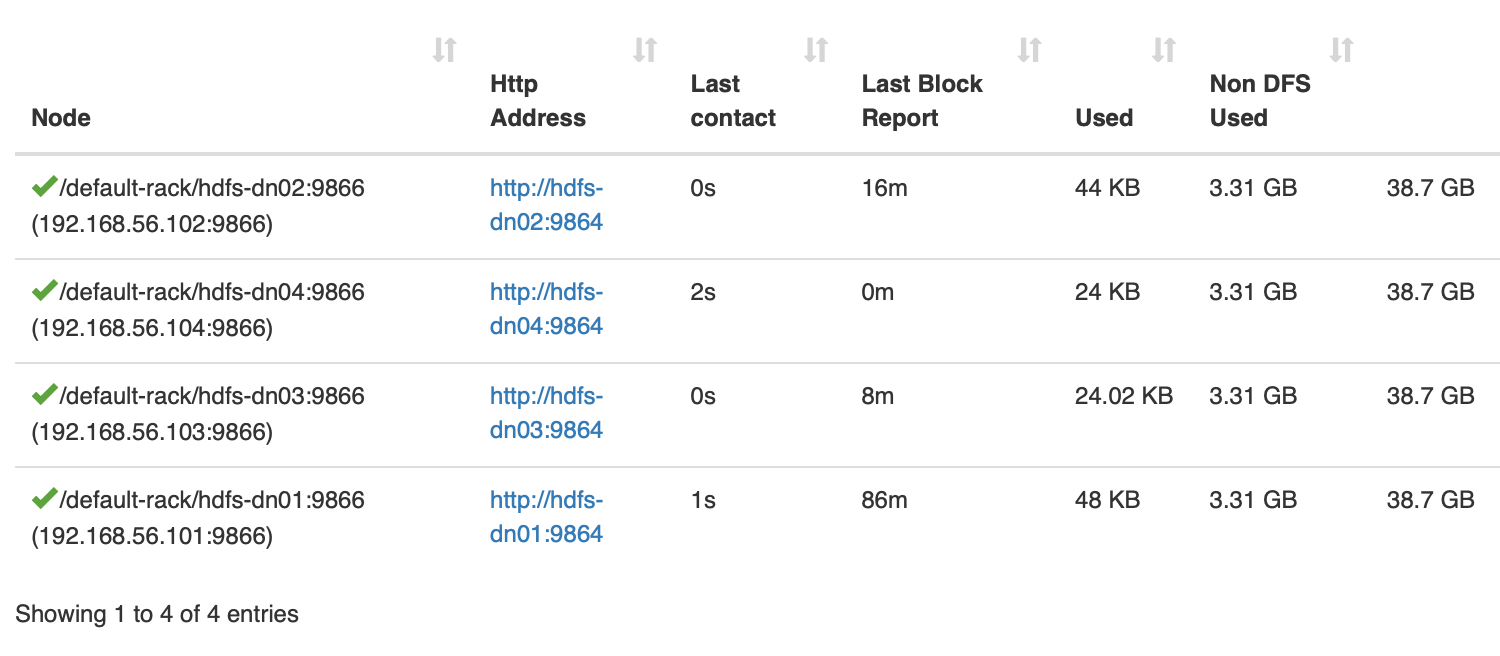
数据块分布到了三个节点vagrant@hdfs-dn03:~$ cat /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0/blk_1073741825仍然看不出数据在冗余到什么程度,还得来一个大杀器 -- 再加一个 hdfs-dn04 数据节点
Hello HDFS
 文件内容分布
文件内容分布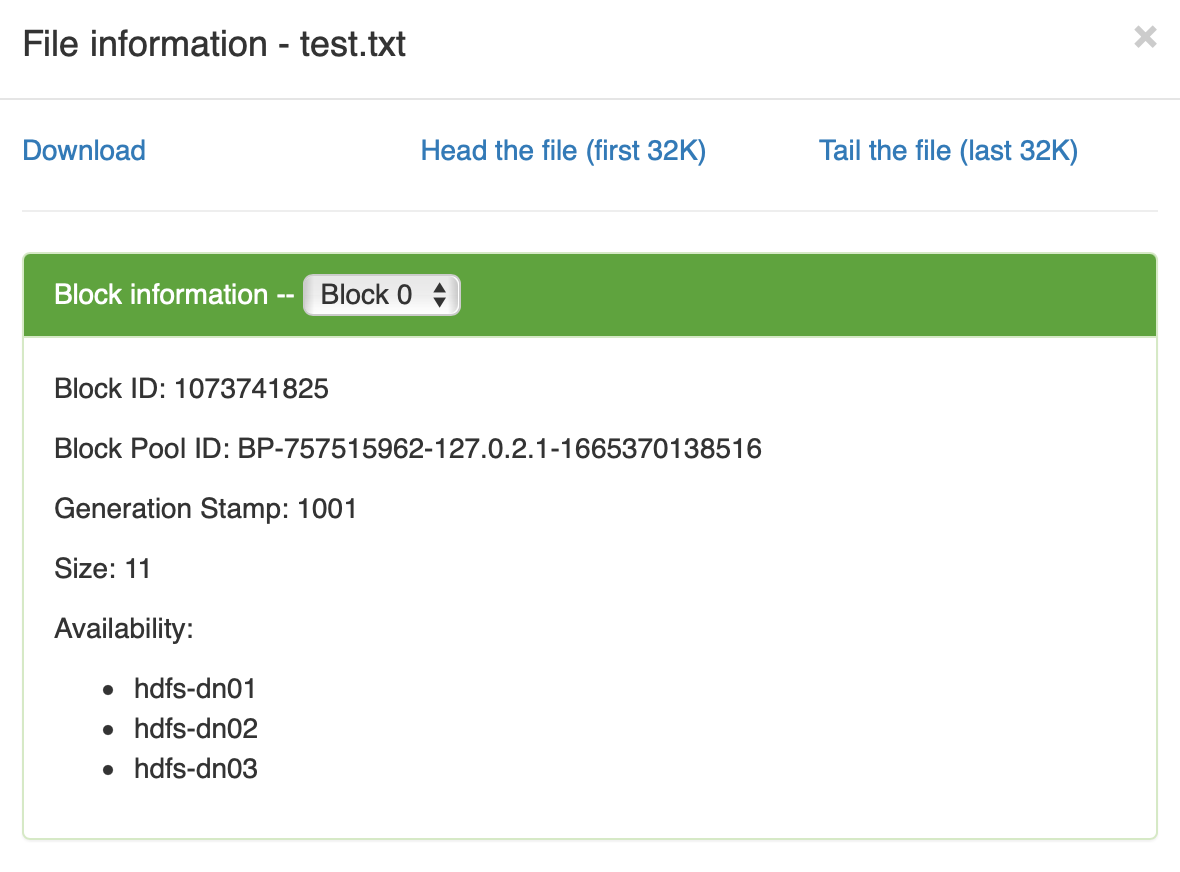 终于不再扩散,默认的冗余存储方式是三份
终于不再扩散,默认的冗余存储方式是三份再创建一个新文件
➜ ~ echo "Hello Test1" > test1.txt数据分布
➜ ~ hdfs dfs -put test1.txt testFolder/
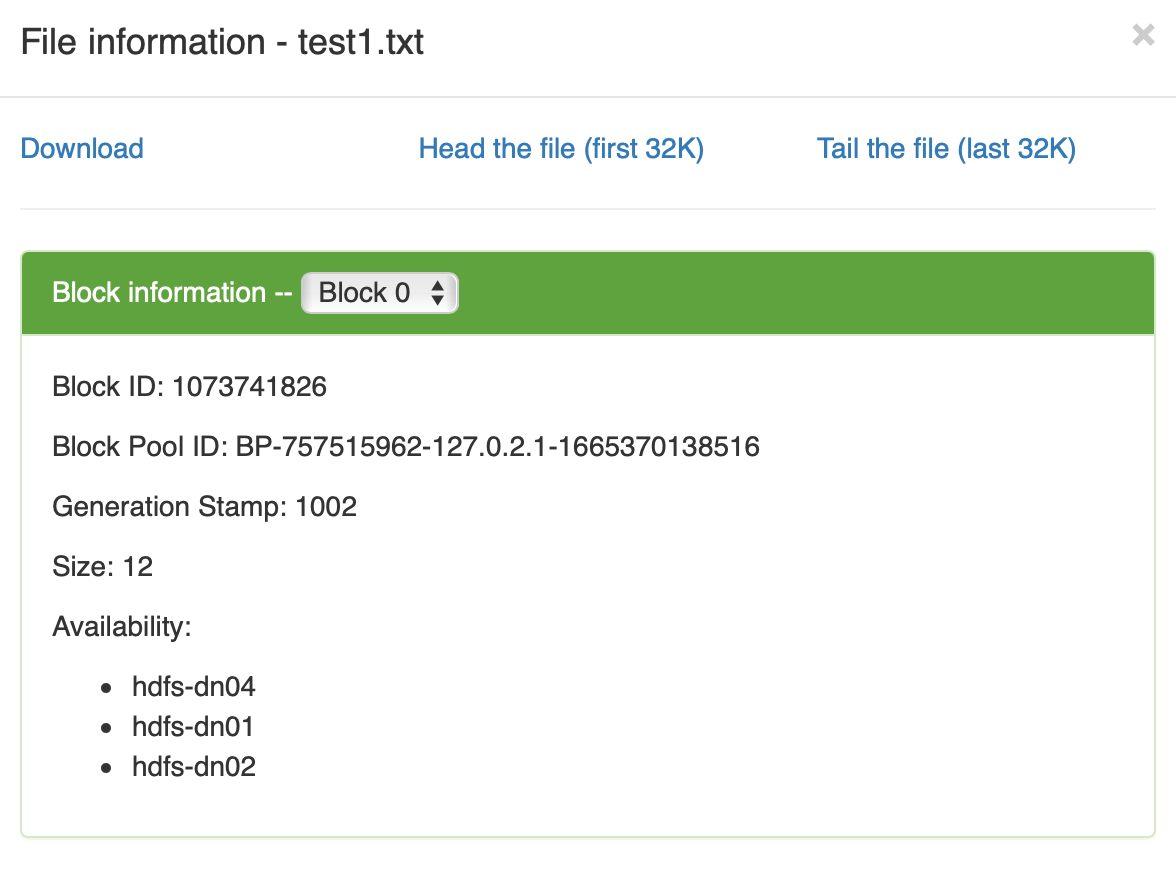 分布在不同的三个数据节点上
分布在不同的三个数据节点上测试一个大文件, 也不用太大,1.2 GB 的 CSV 文件
1➜ Downloads ls -lh big_file.csv
2-rw-r--r-- 1 yanbin staff 1.2G Sep 26 15:44 big_file.csv
3➜ Downloads hdfs dfs -mkdir testFolder2
4➜ Downloads hdfs dfs -put big_file.csv testFolder2/上传完后
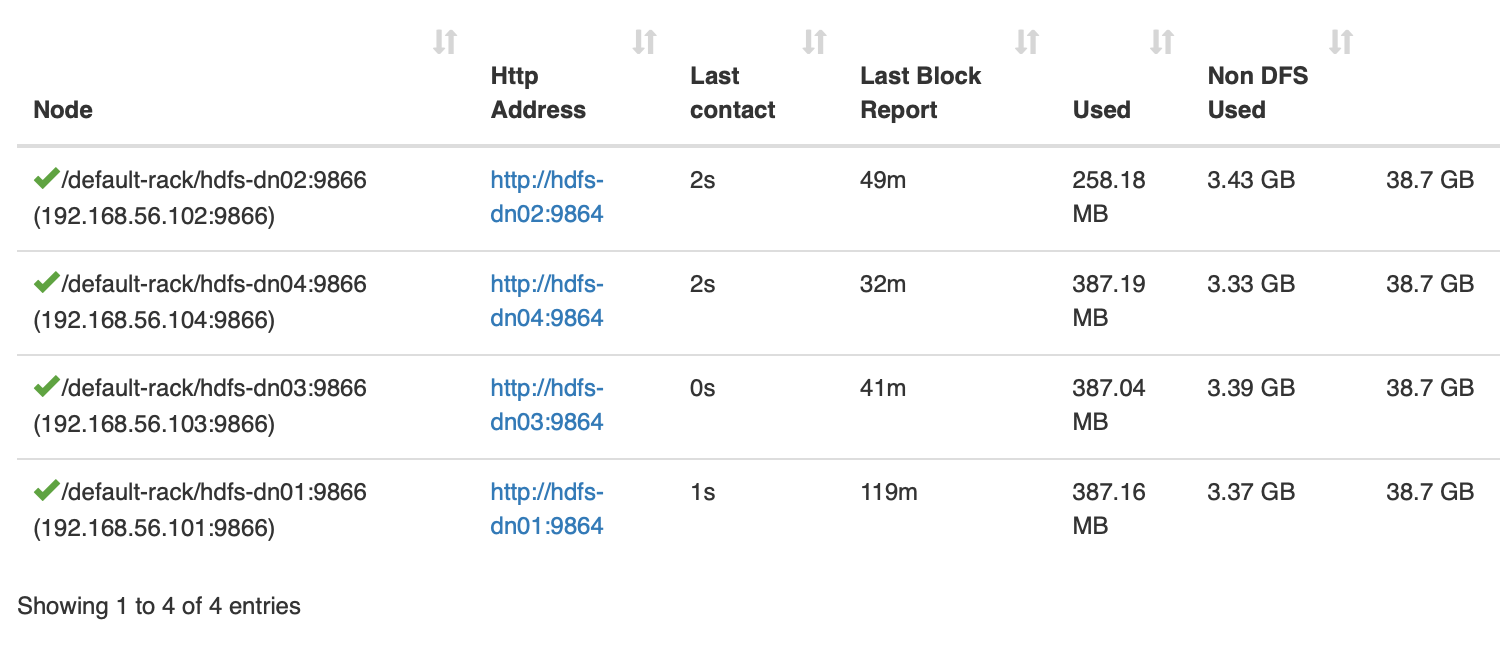

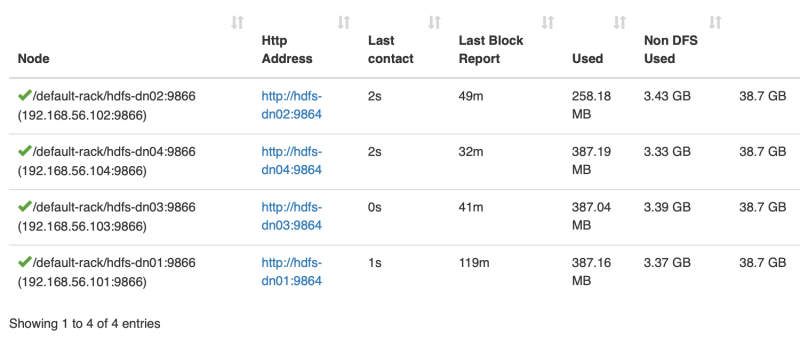
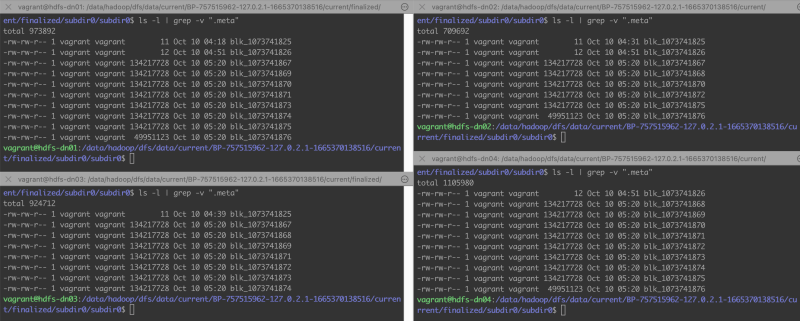
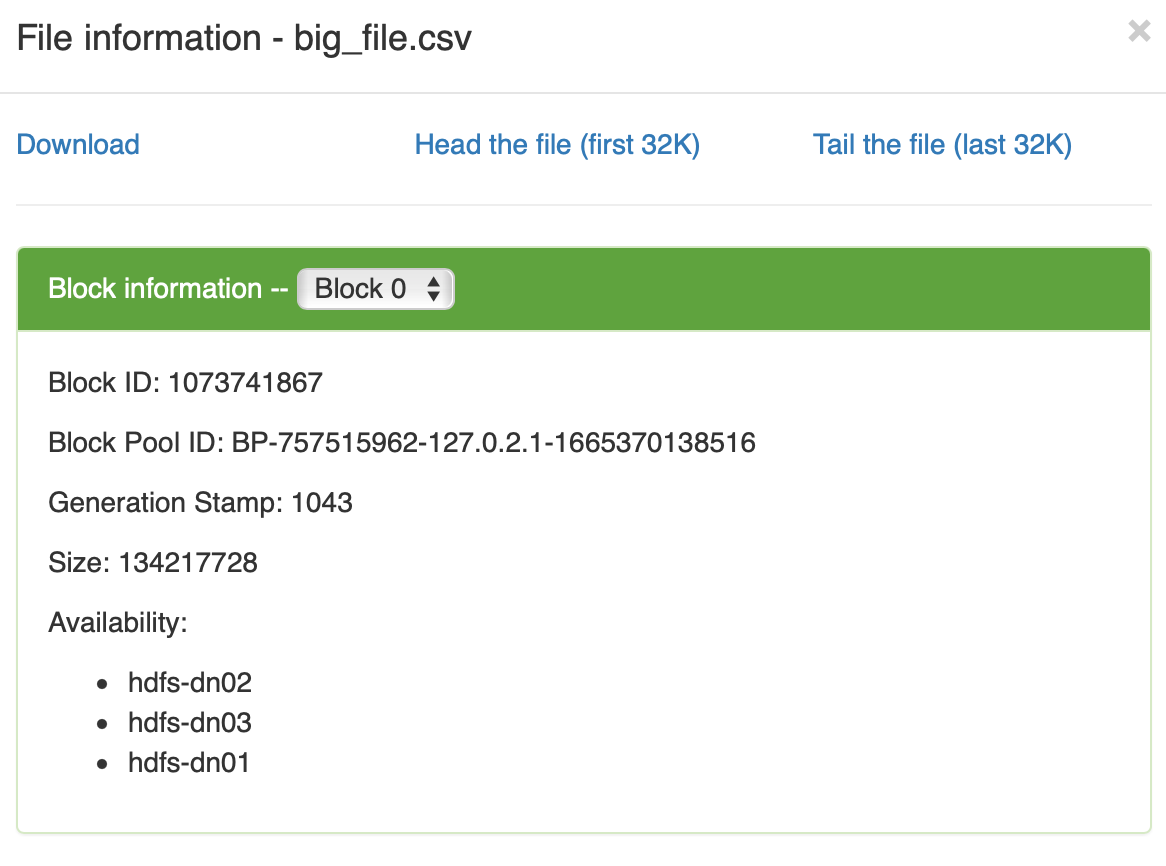 数据块大小为 128M, 数据分布在三个数据节点上,而实际上在所有的四他数据节点上都占用了 2-3 百M的数据大小,似乎每个节点上都有 big_file.csv 的数据文件
数据块大小为 128M, 数据分布在三个数据节点上,而实际上在所有的四他数据节点上都占用了 2-3 百M的数据大小,似乎每个节点上都有 big_file.csv 的数据文件 1vagrant@hdfs-dn02:~$ ls -l /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0
2total 709692
3-rw-rw-r-- 1 vagrant vagrant 11 Oct 10 04:31 blk_1073741825
4-rw-rw-r-- 1 vagrant vagrant 11 Oct 10 04:31 blk_1073741825_1001.meta
5-rw-rw-r-- 1 vagrant vagrant 12 Oct 10 04:51 blk_1073741826
6-rw-rw-r-- 1 vagrant vagrant 11 Oct 10 04:51 blk_1073741826_1002.meta
7-rw-rw-r-- 1 vagrant vagrant 134217728 Oct 10 05:20 blk_1073741867
8-rw-rw-r-- 1 vagrant vagrant 1048583 Oct 10 05:20 blk_1073741867_1043.meta
9-rw-rw-r-- 1 vagrant vagrant 134217728 Oct 10 05:20 blk_1073741868
10-rw-rw-r-- 1 vagrant vagrant 1048583 Oct 10 05:20 blk_1073741868_1044.meta
11......四个节点上都有许多的数据块文件,每个数据块大小限制为 128M。文件信息中说的在 hdfs-dn04 上没有数据,那就专门窥探一下 hdfs-dn04 的数据目录
1vagrant@hdfs-dn04:~$ ls -l /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0
2total 1105980
3-rw-rw-r-- 1 vagrant vagrant 12 Oct 10 04:51 blk_1073741826
4-rw-rw-r-- 1 vagrant vagrant 11 Oct 10 04:51 blk_1073741826_1002.meta
5-rw-rw-r-- 1 vagrant vagrant 134217728 Oct 10 05:20 blk_1073741868
6-rw-rw-r-- 1 vagrant vagrant 1048583 Oct 10 05:20 blk_1073741868_1044.meta
7-rw-rw-r-- 1 vagrant vagrant 134217728 Oct 10 05:20 blk_1073741869
8-rw-rw-r-- 1 vagrant vagrant 1048583 Oct 10 05:20 blk_1073741869_1045.meta
9........这是一个 csv 纯文本文件,所以可以直接查看一下它在 hdfs-dn04 节点中的数据块文件的内容
cat /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0/blk_1073741868显示的又确实是 big_file.csv 文件的内容, 这该如何作出解释呢?实际存储与上面显示的文件信息有点不相符,我们来查看每个 DataNode 的 /data/hadoop/dfs/data/current/BP-757515962-127.0.2.1-1665370138516/current/finalized/subdir0/subdir0 目录来看数据块的分布
.........
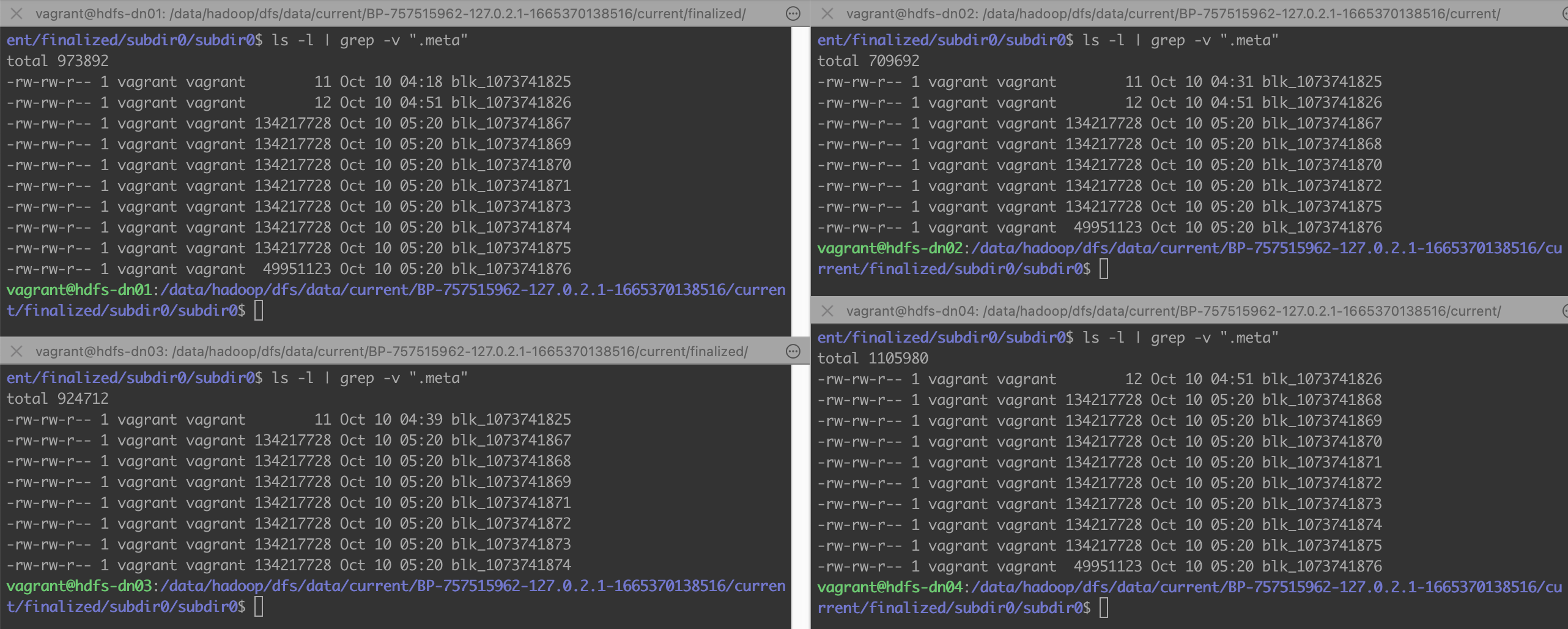 128M 的数据块是属于大文件的,其中
128M 的数据块是属于大文件的,其中| 数据块 | hdfs-dn01 | hdfs-dn02 | hdfs-dn03 | hdfs-dn04 |
| blk_1073741867 | ✔️ | ✔️ | ✔️ | |
| blk_1073741868 | ✔️ | ✔️ | ✔️ | |
| blk_1073741869 | ✔️ | ✔️ | ✔️ |
这涉及到文件块分布的负载均衡的算法,从现在 4 个数据节点,副本数为 3 的情况,从任何两个数据节点都能拼凑出完整的 big_file.csv 文件,换句话说就是数据节点坏一,坏两个都没问题,文件还能正确读取出来,这就是 HDFS 的容错性。
从 Hadoop HDFS - Hadoop Distributed File System 一文中找了一张图
HDFS 的均衡策略和副本个数实现了磁盘阵列的效果,他们实际用途也差不多。如果在 HDFS 集群中缩减了 DataNode 的数目,先前该节点上的数据应该会转移到别的节点上去。后又扩充了更多的 DataNode, 基于访问性能的考虑,HDFS 应该会优化数据块的分布,对数据块进行 Rebalance 操作移动数据。
关于 /etc/hosts 在 Vagrant 中有更好的解决办法
vagrant plugin install vagrant-hostsupdater 可以使用 host 的 /etc/hosts 中的配置,并且每个 vagrant 虚拟机都会向 /etc/hosts 中注册自己,这样就不需要在 NameNode 中编辑 /etc/hosts 文件。
另外,刚看到一个 JuiceFS 文件系统也很好玩,比如挂载一个 redis 缓存,以文件系统的方式来访问
$ juicefs format redis://your-redis-host:6379/1 myjfsHDFS 文件系统也是有办法 mount 到本地目录中来,其后只要以操作本地文件的方式来操作 HDFS 中的文件,比如用 NFS gateway 的方式,NFS -> FUSE -> HDFS。
$ juicefs mount -d redis://your-redis-host:6379/1 /mnt/juicefs
$ cp -r ~/dataset /mnt/juicefs/
链接:
- Hadoop Distributed File Sytem(HDFS)
- 快速搭建 HDFS 系统 (超详细版)
- Secondary NameNode 的作用
- Hadoop之SecondaryNameNode
- Hadoop - 彻底解决 WARN util.NativeCodeLoader: Unable to load native-hadoop library...
- Hadoop: Setting up a Single Node Cluster.
- Hadoop Cluster Setup
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。