 Python 接触的晚,所以接着 体验一下 Python 3.8 带来的主要新特性 继续往前翻,体验一下 Python 3.7 曾经引入的新特性,爱一门语言就要了解她真正的历史。一步一步慢慢给 Python 来个起底。
Python 接触的晚,所以接着 体验一下 Python 3.8 带来的主要新特性 继续往前翻,体验一下 Python 3.7 曾经引入的新特性,爱一门语言就要了解她真正的历史。一步一步慢慢给 Python 来个起底。
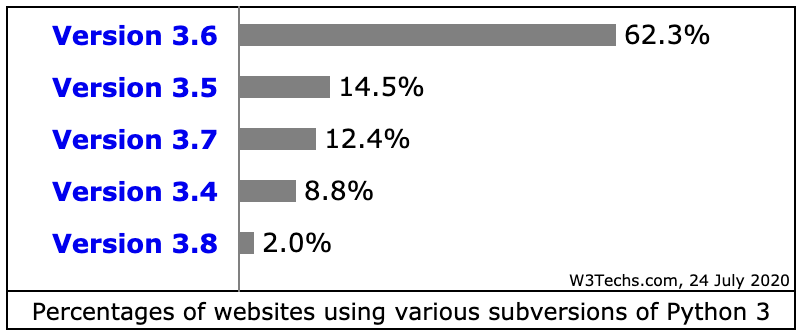
先来看看 Python 网站的各版本使用情况 Usage statistics of Python Version 3 for websites, 这里统计的 Python 开发的网站的数据,应该有 Python 3 大规模的用于其他领域。单网站应用 Python 来说,Python 2 还有大量遗留代码,Python 3 还是 3.6 为主,Python 的升级还任重道远。本人也是谨慎的在从 3.7 迁移到 3.8 的过程中,AWS 的 Lambda 都支持 3.8,直接上 3.8 也没什么历史负担。以下是从网站使用 Python 统计情况中的两个截图
Python 3.7.0 发布于 2018-06-27, 这篇文章 Cool New Features in Python 3.7 详细介绍了 Python 3.7 的新特性,本文也是从其中挑几个来体验体验。 Read More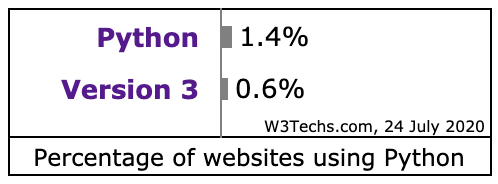
- 在去年的一篇 Python 多线程编程 中学习了 Python 中如何使用多线程来调度任务,工作中也不时从自己的博客中找来参考。在运用当中不时的碰到内存消耗殆尽情况,直接把命令行窗口打死,不得不强行关窗口或杀进程。之前一直未意识到问题所在,只知任务太多就必死无疑,现在要用 Python 来处理大量任务了,必须着手来解决一下它。其实原因很简单,和 Java 的 ThreadPoolExecutor 一样(看它们用的类名都是一样的)。Java 的 ThreadPoolExecutor 内部使用了一个
Integer.MAX_VALUE的 LinkedBlockingQueue 来存放提交的待处理的任务,所以基本上就是一个无底洞,自然解决办法也是类似的,需要一个 Bounded Queue 来存放任务列表。
在解决该问题之前自己也不妨来温习一下 Python 中使用线程池的基本模式,下面的模板代码曾经是我的最爱:1import time 2from concurrent.futures import ThreadPoolExecutor 3 4def perform(x): 5 time.sleep(2) 6 print(f'process {x}') 7 return x + 1 8 9with ThreadPoolExecutor(5) as executor: 10 for i in range(3): 11 executor.submit(perform, i) 12 13 executor.shutdown(wait=True) 14 15print('done')
在上面的with上下文中会进行以下几步 Read More  想要配置好 Apache + mod_wsgi + Flask 问题真是太多了,随便换一个 Linux 发行版,或者不同的 Python 版本就得让 Google 排很多温室气体。Nginx 可以使用 uWSGI 和 Flask 串联起来,配置起来第一直觉好像也不容易,所以打算换一种方式,直接用一个 Python 的 WSGI HTTP Server, 必要的话再往前面加一个反向代理的 Nginx。这里就来试下 Nginx + Gunicorn + Flask 的完整配置。
想要配置好 Apache + mod_wsgi + Flask 问题真是太多了,随便换一个 Linux 发行版,或者不同的 Python 版本就得让 Google 排很多温室气体。Nginx 可以使用 uWSGI 和 Flask 串联起来,配置起来第一直觉好像也不容易,所以打算换一种方式,直接用一个 Python 的 WSGI HTTP Server, 必要的话再往前面加一个反向代理的 Nginx。这里就来试下 Nginx + Gunicorn + Flask 的完整配置。
在 Flask 的官方网站 Deployment Options 提到了各种生产环境下的部署办法,与 Gunicorn 类似的工具还有 uWSGI, Gevent, Twited Web, Hypercorn, Uvicorn, Daphne(来自于 django) Read More- 在 Flask 的官方文档 mod_wsgi(Apache), 说来倒是轻巧,实际操作起来不得不时刻要凝视眼前的无数大坑,或许 Linux, Apache 都用上比较新的版本会好一些。而我所用的环境是 AWS 上的 EC2, AMI 镜像发行版用 cat /proc/version 看到的是 Red Hat 7.2.1-2,内核为 4.14。照着 Flask 的官方文档是没做成功的,yum install mod_wsgi 只能安装到 Python2 的模块,pip install mod_wsgi 也不成功,所以只能使用 mod_wsgi 的源码来编译安装。
要能顺利编译过 mod_wsgi, 需要安装 Apache 2.2 和 Python 3.6 的 dev 版本。它的仓库里 Python3 最高版本只有 Python 3.6,要 Python 3.7, 3.8 可从源码编译安装。$ yum install gcc
Red Hat 7.2 下的 Apache 真心的难用,不叫 Apache2 也不叫 httpd2,不像 Debian 系统下的 Apache2 做了模块化,基本上 Red Hat 7.2 的 httpd 的配置全在一个文件中 /etc/httpd/conf/httpd.conf。 Read More
$ yum install httpd-devel
$ yum install python36-devel - 本来只是为了研究一下 Flask 怎么去支持早已在 Python 的支持的 coroutine 功能,没想步子越迈越大,直顶到 aiohttp Web 服务器和 Flask 的异步实现版本 Quart。Flask 得费了好一番功夫去获得
EventLoop,可知 aiohttp 和 Quart 的路由方法直接就允许async的,那个EventLoop自然就在其中。从async的路由方法出发去调用别的异步方法就是一件十分轻松的事情。
下面来稍稍体验一下用分别用 aiohttp 和 Quart 实现简单的异步服务器,我们的关注点在它的异步路由。
Read More - 源于自己折腾的一个小 Flask 项目中,后台需访问多个 HTTP 服务,目前采用 ThreadPoolExecutor 多线程的方式处理的。但因访问 HTTP 服务有前后关联关系,如得到请求 A 的结果后再访问 B,这似乎用 Promise.then().then() 编程方式更合适些。于是巡着这一路子,翻出 Python 的各种相关部件来,比如 Python 对 coroutine(协程) 的支持,asyncio, 及后面的 async/await 关键子,aiohttp 组件,requests 的 async 替代品有 aiohttp, grequests, 和 httpx,aiohttp 可替代 Flask, 最后竟然找到了一个更彻底的 Flask 的 Async 版本 Quart。
Python 3.4 引入了 asyncio 模块,基于生成器(yield 和 yield from) 和 @asyncio.coroutine 的方式来支持 coroutine(协程), 到 Python 3.5 后有了 async/await(@asyncio.corouting 替换为 async, yield from 替换为 await) 关键字,协程的实现变得更为简单。Python 3.4 使用 coroutine 的方式我们跳过,直接看
Read More - 在 Python 常用日期处理 -- 内置模块 datetime 探讨了 Python 如何使用 datetime, 如果是一个跨时区的应用(Web 应用都是),就不能只存储一个时间而不带时区,如此,全球用户将会看到一个相同的时间字符串,白天黑夜就错乱了。比说用户信息的更新时间存储为 2020-07-07 13:46:08, 上海的用户和芝加哥的用户看到的是同一个时间字符串,实质上却相差好多个小时。
我们可以这么做,在服务端只存储一个 Timestamp 长整型值或 UTC 时间,Timestamp 是无关乎时区的,它总是相对于一个 UTC 时间的偏移值; 然后由客户端根据本地时区来显示当地时间。不过在服务端存储为 Timestamp 或 UTC 可读性就不强了,打开文件看到 Timestamp 整形值,大脑是无法直接转换为日期,UTC 时间略好一些。
另一种做法可在服务端存储为开发者便于理解的带时区的时间,如 2020-07-07T13:46:08.342+08:00, 客户获得该时间,因为带有时区信息也就能转换为客户端本地时间。
客户端请求时还可以把本地的时区信息传送给服务端,由服务端转换为相应的本地时间发送给客户端,但 HTTP 头信息默认不带时区信息,客户端必须主动发送它。 Read More  紧接上一篇 Flask 和 Vue.js 开发及整合部署实例,来体验一下它们与 Bootstrap/BootstrapVue 的集成。漂亮的网站少不得一个好的 CSS 框架,现在有许许多的 CSS 框架可选,纯 CSS 的, 轻量级的, 含 JS 的 CSS 框架,如 Pure, Bulma, Spectre, 国产的 Element 等。而我总觉得 Bootstrap 更是五臟俱全,像 Element 专为 Vue.js 打造的一样,Bootstrap 也有 BootstrpVue 那样一个结晶品。
紧接上一篇 Flask 和 Vue.js 开发及整合部署实例,来体验一下它们与 Bootstrap/BootstrapVue 的集成。漂亮的网站少不得一个好的 CSS 框架,现在有许许多的 CSS 框架可选,纯 CSS 的, 轻量级的, 含 JS 的 CSS 框架,如 Pure, Bulma, Spectre, 国产的 Element 等。而我总觉得 Bootstrap 更是五臟俱全,像 Element 专为 Vue.js 打造的一样,Bootstrap 也有 BootstrpVue 那样一个结晶品。
本文准确的内容应该是关于 Vue.js 与 Bootstrap/BootstrapVue 的话题,与 Flask 没什么事,不过这里呢,还是强拉上 Flask, 由 Flask 的 API 来产生一些数据。
同样是阅读 Flask和Vue.js构建全栈单页面web应用【通过Flask开发RESTful API】的一个实践品。本篇基于 Flask 和 Vue.js 开发及整合部署实例 中的步骤建立的项目 flask-vue-app,方便起见,用了一个新项目名称 flask-vue-bootstrap。记得我们为 Flask 和 Vue.js 分别建立了 backend 和 frontend 两个子项目。 Read More- 想做些简单的 Web 工具,首先想到的是 Flask + Vue.js, 当然可以完全用 Flask 自己的页面模板 Jinja2, 但一个网站项目不能享受到像 Vue.js, React 类似框架的灵活性真是太可惜了。于是 Flask 只专注于 API, 页面逻辑全用 Vue.js 的组合就成了我的首选,Flask 方面还能进一步选择 FlaskRESTful 框架。还需做得更漂亮的话,CSS 框架可选择 Bootstrap 或与 Vue 紧密集成的 BootstrapVue, 这是后话。
本文主要参考 Flask和Vue.js构建全栈单页面web应用【通过Flask开发RESTful API】的前部分,英文原文在这里 Developing a Single Page App with Flask and Vue.js。
开发过程中我们可以保持 Flask 和 Vue.js 为单独的两个项目,并启动各自的服务,比如 Flask 是 http://localhost:5000, Vue.js 项目通过npm run serve启动在 http://localhost:8080,借助于 node js 的功能,修改 Vue.js 项目的内容能够自动刷新网页。要是开发中把静态文件全放在 Flask 项目中,那么任何对静态文件的修改都必须重启 Flask 服务。虽然 Debug 模式启动的 Flask 在看到它的目录中有任何修改时也能自动重启,但对静态文件的修改重启 Flask 没这个必要性。
但部署时需进一步整合,最终只需要启动 Flask 服务,而无须两个,方便部署。如果是以 Docker 容器的方式发布,使用 docker-compose 来编排两个容器来发布也还算不错。更专业的部署方式应该是 Vue.js 的静态内容放到专门的 Web 服务器,如 Apache/Nginx 中,Flask 也通过 wsgi 与 Web 服务器集成起来。 Read More